我正在测试新的CUDA 8和Pascal Titan X GPU,期望我的代码能够加速,但由于某些原因,它变得更慢了。我使用的是Ubuntu 16.04。
以下是能够重现结果的最小代码:
CUDASample.cuh
class CUDASample{
public:
void AddOneToVector(std::vector<int> &in);
};
CUDASample.cu
__global__ static void CUDAKernelAddOneToVector(int *data)
{
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
const int mx = gridDim.x * blockDim.x;
data[y * mx + x] = data[y * mx + x] + 1.0f;
}
void CUDASample::AddOneToVector(std::vector<int> &in){
int *data;
cudaMallocManaged(reinterpret_cast<void **>(&data),
in.size() * sizeof(int),
cudaMemAttachGlobal);
for (std::size_t i = 0; i < in.size(); i++){
data[i] = in.at(i);
}
dim3 blks(in.size()/(16*32),1);
dim3 threads(32, 16);
CUDAKernelAddOneToVector<<<blks, threads>>>(data);
cudaDeviceSynchronize();
for (std::size_t i = 0; i < in.size(); i++){
in.at(i) = data[i];
}
cudaFree(data);
}
Main.cpp
std::vector<int> v;
for (int i = 0; i < 8192000; i++){
v.push_back(i);
}
CUDASample cudasample;
cudasample.AddOneToVector(v);
唯一的区别在于NVCC标志,对于Pascal Titan X而言是:
-gencode arch=compute_61,code=sm_61-std=c++11;
对于旧版的Maxwell Titan X而言:
-gencode arch=compute_52,code=sm_52-std=c++11;
编辑:以下是运行NVIDIA可视化分析的结果。
对于旧的Maxwell Titan,内存传输时间约为205毫秒,核启动时间约为268微秒。
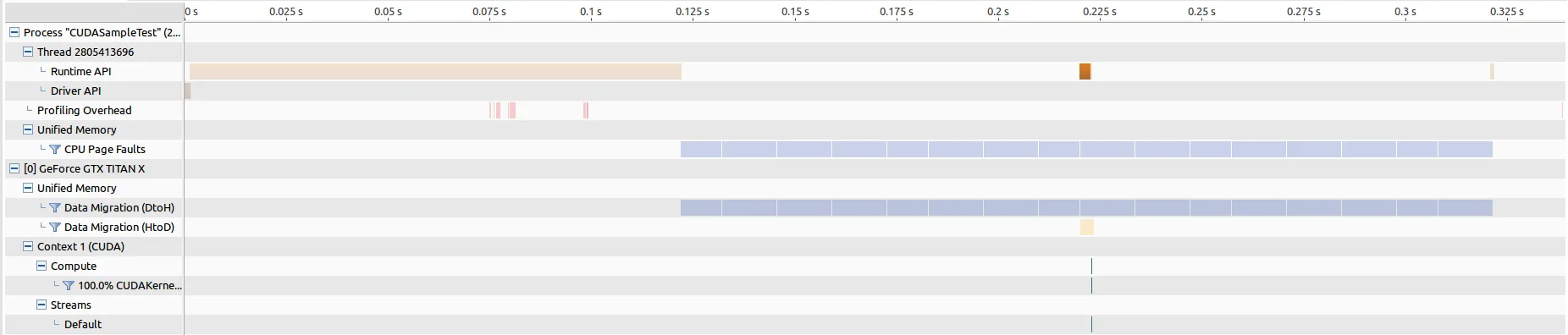
对于Pascal Titan,内存传输时间约为202毫秒,核启动时间约为惊人的8343微秒,这让我认为出现了一些问题。
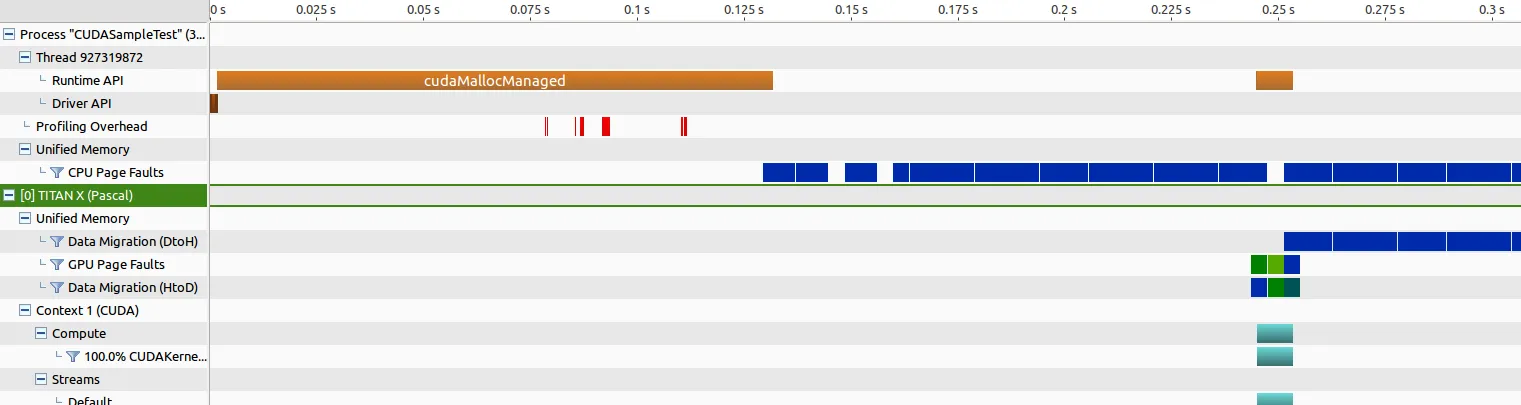
我进一步通过将cudaMallocManaged替换为老式的cudaMalloc并进行一些分析来排除问题,并观察到一些有趣的结果。
CUDASample.cu
__global__ static void CUDAKernelAddOneToVector(int *data)
{
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
const int mx = gridDim.x * blockDim.x;
data[y * mx + x] = data[y * mx + x] + 1.0f;
}
void CUDASample::AddOneToVector(std::vector<int> &in){
int *data;
cudaMalloc(reinterpret_cast<void **>(&data), in.size() * sizeof(int));
cudaMemcpy(reinterpret_cast<void*>(data),reinterpret_cast<void*>(in.data()),
in.size() * sizeof(int), cudaMemcpyHostToDevice);
dim3 blks(in.size()/(16*32),1);
dim3 threads(32, 16);
CUDAKernelAddOneToVector<<<blks, threads>>>(data);
cudaDeviceSynchronize();
cudaMemcpy(reinterpret_cast<void*>(in.data()),reinterpret_cast<void*>(data),
in.size() * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(data);
}
旧的Maxwell Titan的内存传输时间大约为5毫秒,双向均是如此,核心启动时间则为264微秒。
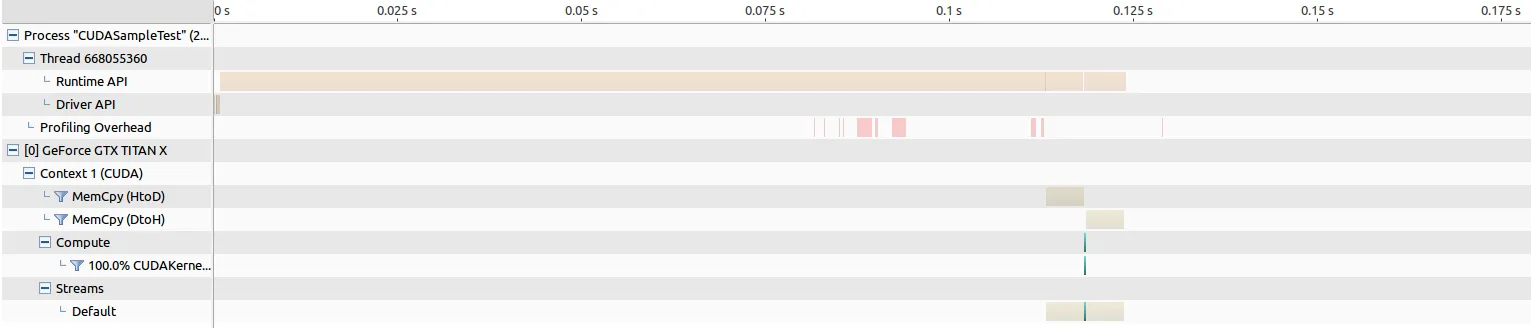
Pascal Titan的内存传输时间也是双向都约为5毫秒,但核心启动时间只有194微秒,这导致了我希望看到的性能提升…

为什么使用cudaMallocManaged时,Pascal GPU在运行CUDA核函数时如此缓慢?如果我必须将所有现有使用cudaMallocManaged的代码还原为cudaMalloc,则这将是一场灾难。这个实验还表明,使用cudaMallocManaged进行内存传输的时间比使用cudaMalloc要慢得多,这也感觉有些不对劲。如果使用这种方法会导致运行时间变慢,即使代码更易于编写,这也应该是不可接受的,因为使用CUDA而不是纯C++的整个目的就是为了加速。我做错了什么,为什么出现这种结果?
- 向量加法并不是测试GPU速度的特别有趣的测试。
- 不可能准确地知道你正在测量什么,以及如何测量。
- 在任何GPU上,4096个元素的向量加法内核都不应该需要花费约70毫秒的时间。70微秒更为合理。这是一个非常微小的问题,你几乎可以确定正在测量某种开销,而不是实际的GPU计算性能。
- Robert Crovellanvprof运行代码。 在新的Titan X上,第二次调用内核应该运行得更快。 - Robert Crovella