有多个关于此主题的SO问题,但它们似乎都非常低效,因为它们都涉及将整个文件复制以仅删除单个行。 如果我有一个像这样格式化的csv:
fname,lname,age,sex
John,Doe,28,m
Sarah,Smith,27,f
Xavier,Moore,19,m
最有效的删除Sarah行的方法是什么?如果可能的话,我想避免复制整个文件。
有多个关于此主题的SO问题,但它们似乎都非常低效,因为它们都涉及将整个文件复制以仅删除单个行。 如果我有一个像这样格式化的csv:
fname,lname,age,sex
John,Doe,28,m
Sarah,Smith,27,f
Xavier,Moore,19,m
最有效的删除Sarah行的方法是什么?如果可能的话,我想避免复制整个文件。
你们面临一个根本性的问题。就我所知,目前没有任何文件系统提供删除文件中一段字节的功能。你可以覆盖现有的字节或者写入一个新文件,所以你的选择如下:
\0。但如果要保持通用性,则对于 CSV 文件而言这不可行,因为 CSV 文件中没有定义注释符号。显然,如果你要删除第一行,最后一种方法并不能帮助你(但如果你要删除靠近文件末尾的一行,这个方法还是很有用的)。此外,该方法在操作过程中很容易崩溃。
在原地编辑文件是一个充满陷阱的任务(就像在迭代过程中修改可迭代对象一样),通常不值得麻烦。在大多数情况下,写入临时文件(或根据您拥有的存储空间或RAM而选择使用工作内存),然后删除源文件并用临时文件替换源文件将与尝试在原地执行相同操作具有相同的性能。
但是,如果您坚持要这样做,这里是一个通用解决方案:
import os
def remove_line(path, comp):
with open(path, "r+b") as f: # open the file in rw mode
mod_lines = 0 # hold the overwrite offset
while True:
last_pos = f.tell() # keep the last line position
line = f.readline() # read the next line
if not line: # EOF
break
if mod_lines: # we've already encountered what we search for
f.seek(last_pos - mod_lines) # move back to the beginning of the gap
f.write(line) # fill the gap with the current line
f.seek(mod_lines, os.SEEK_CUR) # move forward til the next line start
elif comp(line): # search for our data
mod_lines = len(line) # store the offset when found to create a gap
f.seek(last_pos - mod_lines) # seek back the extra removed characters
f.truncate() # truncate the rest
这将仅删除与提供的比较函数相匹配的行,然后迭代文件的其余部分,将数据移到“已删除”行上。您也不需要将文件的其余部分加载到您的工作内存中。要测试它,请使用包含以下内容的test.csv运行:
fname,lname,age,sex John,Doe,28,m Sarah,Smith,27,f Xavier,Moore,19,m
可以这样运行:
remove_line("test.csv", lambda x: x.startswith(b"Sarah"))
当你执行以下操作时,将得到一个test.csv文件,并删除其中的Sarah行:
fname,lname,age,sex John,Doe,28,m Xavier,Moore,19,m
请记住,在二进制模式下打开文件时,我们正在传递一个bytes比较函数,以保持一致的换行符而截断/覆盖文件。
更新:我对这里介绍的各种技术的实际性能很感兴趣,但昨天我没有��间测试它们,所以稍有延迟,我创建了一个基准测试,可以揭示一些信息。如果您只关心结果,请直接滚动到底部。首先我会解释我在进行基准测试方面的具体做法并提供所有脚本,以便您可以在自己的系统上运行相同的基准测试。
至于我测试什么,我测试了所有在此和其他答案中提到的技术,即使用临时文件进行行替换(temp_file_*函数)和使用就地编辑(in_place_*)函数。我都将其设置为流模式(逐行读取,*_stream函数)和内存模式(在工作内存中读取文件的其余部分,*_wm函数)。我还添加了使用mmap模块的原地行删除技术(in_place_mmap函数)。包含所有这些函数以及一小段逻辑用于通过CLI控制的基准测试脚本如下:
#!/usr/bin/env python
import mmap
import os
import shutil
import sys
import time
def get_temporary_path(path): # use tempfile facilities in production
folder, filename = os.path.split(path)
return os.path.join(folder, "~$" + filename)
def temp_file_wm(path, comp):
path_out = get_temporary_path(path)
with open(path, "rb") as f_in, open(path_out, "wb") as f_out:
while True:
line = f_in.readline()
if not line:
break
if comp(line):
f_out.write(f_in.read())
break
else:
f_out.write(line)
f_out.flush()
os.fsync(f_out.fileno())
shutil.move(path_out, path)
def temp_file_stream(path, comp):
path_out = get_temporary_path(path)
not_found = True # a flag to stop comparison after the first match, for fairness
with open(path, "rb") as f_in, open(path_out, "wb") as f_out:
while True:
line = f_in.readline()
if not line:
break
if not_found and comp(line):
continue
f_out.write(line)
f_out.flush()
os.fsync(f_out.fileno())
shutil.move(path_out, path)
def in_place_wm(path, comp):
with open(path, "r+b") as f:
while True:
last_pos = f.tell()
line = f.readline()
if not line:
break
if comp(line):
rest = f.read()
f.seek(last_pos)
f.write(rest)
break
f.truncate()
f.flush()
os.fsync(f.fileno())
def in_place_stream(path, comp):
with open(path, "r+b") as f:
mod_lines = 0
while True:
last_pos = f.tell()
line = f.readline()
if not line:
break
if mod_lines:
f.seek(last_pos - mod_lines)
f.write(line)
f.seek(mod_lines, os.SEEK_CUR)
elif comp(line):
mod_lines = len(line)
f.seek(last_pos - mod_lines)
f.truncate()
f.flush()
os.fsync(f.fileno())
def in_place_mmap(path, comp):
with open(path, "r+b") as f:
stream = mmap.mmap(f.fileno(), 0)
total_size = len(stream)
while True:
last_pos = stream.tell()
line = stream.readline()
if not line:
break
if comp(line):
current_pos = stream.tell()
stream.move(last_pos, current_pos, total_size - current_pos)
total_size -= len(line)
break
stream.flush()
stream.close()
f.truncate(total_size)
f.flush()
os.fsync(f.fileno())
if __name__ == "__main__":
if len(sys.argv) < 3:
print("Usage: {} target_file.ext <search_string> [function_name]".format(__file__))
exit(1)
target_file = sys.argv[1]
search_func = globals().get(sys.argv[3] if len(sys.argv) > 3 else None, in_place_wm)
start_time = time.time()
search_func(target_file, lambda x: x.startswith(sys.argv[2].encode("utf-8")))
# some info for the test runner...
print("python_version: " + sys.version.split()[0])
print("python_time: {:.2f}".format(time.time() - start_time))
chrt -f 99) 和 /usr/bin/time 进行基准测试,因为 Python 在像这样的场景中无法真正信任其性能测量。不幸的是,我手头没有完全隔离运行测试的系统,因此我的数据是从在虚拟机中运行测试中获得的。这意味着 I/O 性能可能非常倾斜,但它应该同样影响所有测试,仍然提供可比较的数据。无论如何,您可以在自己的系统上运行此测试,以获取您可以关联的结果。
我设置了一个执行上述方案的测试脚本:
#!/usr/bin/env python
import collections
import os
import random
import shutil
import subprocess
import sys
import time
try:
range = xrange # cover Python 2.x
except NameError:
pass
try:
DEV_NULL = subprocess.DEVNULL
except AttributeError:
DEV_NULL = open(os.devnull, "wb") # cover Python 2.x
SAMPLE_ROWS = 10**6 # 1M lines
TEST_LOOPS = 3
CALL_SCRIPT = os.path.join(os.getcwd(), "remove_line.py") # the above script
def get_temporary_path(path):
folder, filename = os.path.split(path)
return os.path.join(folder, "~$" + filename)
def generate_samples(path, data="LINE", rows=10**6, columns=10): # 1Mx10 default matrix
sample_beginning = os.path.join(path, "sample_beg.csv")
sample_middle = os.path.join(path, "sample_mid.csv")
sample_end = os.path.join(path, "sample_end.csv")
separator = os.linesep
middle_row = rows // 2
with open(sample_beginning, "w") as f_b, \
open(sample_middle, "w") as f_m, \
open(sample_end, "w") as f_e:
f_b.write(data)
f_b.write(separator)
for i in range(rows):
if not i % middle_row:
f_m.write(data)
f_m.write(separator)
for t in (f_b, f_m, f_e):
t.write(",".join((str(random.random()) for _ in range(columns))))
t.write(separator)
f_e.write(data)
f_e.write(separator)
return ("beginning", sample_beginning), ("middle", sample_middle), ("end", sample_end)
def normalize_field(field):
field = field.lower()
while True:
s_index = field.find('(')
e_index = field.find(')')
if s_index == -1 or e_index == -1:
break
field = field[:s_index] + field[e_index + 1:]
return "_".join(field.split())
def encode_csv_field(field):
if isinstance(field, (int, float)):
field = str(field)
escape = False
if '"' in field:
escape = True
field = field.replace('"', '""')
elif "," in field or "\n" in field:
escape = True
if escape:
return ('"' + field + '"').encode("utf-8")
return field.encode("utf-8")
if __name__ == "__main__":
print("Generating sample data...")
start_time = time.time()
samples = generate_samples(os.getcwd(), "REMOVE THIS LINE", SAMPLE_ROWS)
print("Done, generation took: {:2} seconds.".format(time.time() - start_time))
print("Beginning tests...")
search_string = "REMOVE"
header = None
results = []
for f in ("temp_file_stream", "temp_file_wm",
"in_place_stream", "in_place_wm", "in_place_mmap"):
for s, path in samples:
for test in range(TEST_LOOPS):
result = collections.OrderedDict((("function", f), ("sample", s),
("test", test)))
print("Running {function} test, {sample} #{test}...".format(**result))
temp_sample = get_temporary_path(path)
shutil.copy(path, temp_sample)
print(" Clearing caches...")
subprocess.call(["sudo", "/usr/bin/sync"], stdout=DEV_NULL)
with open("/proc/sys/vm/drop_caches", "w") as dc:
dc.write("3\n") # free pagecache, inodes, dentries...
# you can add more cache clearing/invalidating calls here...
print(" Removing a line starting with `{}`...".format(search_string))
out = subprocess.check_output(["sudo", "chrt", "-f", "99",
"/usr/bin/time", "--verbose",
sys.executable, CALL_SCRIPT, temp_sample,
search_string, f], stderr=subprocess.STDOUT)
print(" Cleaning up...")
os.remove(temp_sample)
for line in out.decode("utf-8").split("\n"):
pair = line.strip().rsplit(": ", 1)
if len(pair) >= 2:
result[normalize_field(pair[0].strip())] = pair[1].strip()
results.append(result)
if not header: # store the header for later reference
header = result.keys()
print("Cleaning up sample data...")
for s, path in samples:
os.remove(path)
output_file = sys.argv[1] if len(sys.argv) > 1 else "results.csv"
output_results = os.path.join(os.getcwd(), output_file)
print("All tests completed, writing results to: " + output_results)
with open(output_results, "wb") as f:
f.write(b",".join(encode_csv_field(k) for k in header) + b"\n")
for result in results:
f.write(b",".join(encode_csv_field(v) for v in result.values()) + b"\n")
print("All done.")
最终结果(太长不看):我从结果集中仅提取了最佳时间和内存数据,但您可以在此处获取完整的结果集:Python 2.7 原始测试数据 和 Python 3.6 原始测试数据。
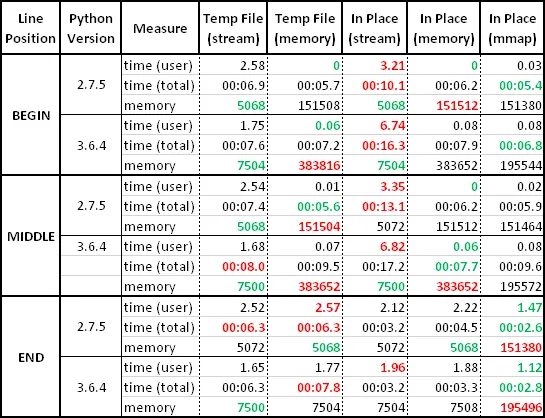
基于我收集的数据,以下是一些最终说明:
*_stream 函数提供小的内存占用。在 Python 3.x 中,mmap 技术可作为一种折衷方案。in_place_* 函数才是可行的选择。in_place_stream,但会牺牲处理时间和增加 I/O 调用(与 *_wm 函数相比)。in_place_* 函数是危险的,因为如果在中途停止,则可能导致数据损坏。没有完整性检查的 temp_file_* 函数仅在非事务性文件系统上存在风险。这是一种方法。您需要将文件的其余部分加载到缓冲区中,但这是我在Python中能想到的最好方法:
with open('afile','r+') as fd:
delLine = 4
for i in range(delLine):
pos = fd.tell()
fd.readline()
rest = fd.read()
fd.seek(pos)
fd.truncate()
fd.write(rest)
fd.close()
pos = fd.tell()
while fd.readline().startswith('Sarah'): pos = fd.tell()
如果找不到'Sarah',则会出现异常。
如果要删除的行靠近结尾,这可能更有效,但我不确定读取所有内容,删除该行并将其转储回文件是否可以节省用户时间(考虑到这是Tk应用程序)。此外,它只需要打开和刷新文件一次,因此除非文件非常长且Sarah离下面很远,否则可能不会引起注意。
dd),唯一的区别是不需要一次性读取文件的其余部分(可能会导致内存耗尽)。相反,您只需要读取与删除的行相同大小的块。我认为这在Python中应该很容易实现。 - Digital Trauma使用sed命令:
sed -ie "/Sahra/d" your_file
import pandas as pd
df = pd.read_csv('data.csv')
df = df[df.fname != 'Sarah' ]
df.to_csv('data.csv', index=False)
'' 覆盖所有内容,不是吗? - kabanus这可能有帮助:
with open("sample.csv",'r') as f:
for line in f:
if line.startswith('sarah'):continue
print(line)
print是一个函数。 - Chris_Rands
sed/awk/grep呢?如果你想做其他事情,那么在Python中迭代文件可能是必要的,所以朴素的方法是可以的。 - Chris_Randsr+选项打开文件,以便同时进行读取和写入。 - Chris_Rands