我想删除CSV文件字段数据中的换行符。在SO /其他地方,多个人提出了同样的问题。但是,提供的解决方案都是脚本语言。我正在寻找编程语言(如PYTHON或Spark)的解决方案(不仅限于这两种语言),因为我的文件非常大。
新行字符可以出现在任何字段的数据中。
编辑: 根据代码的屏幕截图:
以前关于同一主题的问题:
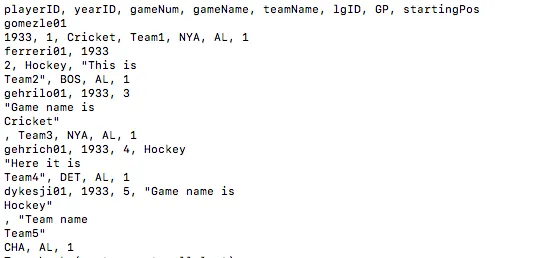
playerID,yearID,gameNum,gameName,teamName,lgID,GP,startingPos
gomezle01,1933,1,Cricket,Team1,NYA,AL,1
ferreri01,1933,2,Hockey,"This is
Team2",BOS,AL,1
gehrilo01,1933,3,"Game name is
Cricket"
,Team3,NYA,AL,1
gehrich01,1933,4,Hockey,"Here it is
Team4",DET,AL,1
dykesji01,1933,5,"Game name is
Hockey"
,"Team name
Team5",CHA,AL,1
期望输出:
playerID,yearID,gameNum,gameName,teamName,lgID,GP,startingPos
gomezle01,1933,1,Cricket,Team1,NYA,AL,1
ferreri01,1933,2,Hockey,"This is Team2",BOS,AL,1
gehrilo01,1933,3,"Game name is Cricket" ,Team3,NYA,AL,1
gehrich01,1933,4,Hockey,"Here it is Team4",DET,AL,1
dykesji01,1933,5,"Game name is Hockey","Team name Team5",CHA,AL,1
新行字符可以出现在任何字段的数据中。
编辑: 根据代码的屏幕截图: