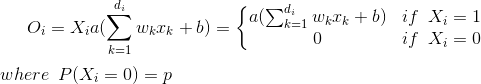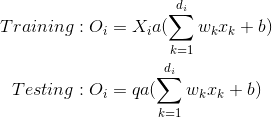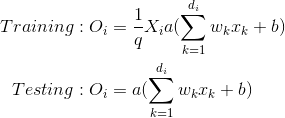这段代码尝试使用自定义的dropout实现:
%reset -f
import torch
import torch.nn as nn
# import torchvision
# import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.utils.data as data_utils
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
num_epochs = 1000
number_samples = 10
from sklearn.datasets import make_moons
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_moons(n_samples=number_samples, noise=0.1)
# scatter plot, dots colored by class value
x_data = [a for a in enumerate(X)]
x_data_train = x_data[:int(len(x_data) * .5)]
x_data_train = [i[1] for i in x_data_train]
x_data_train
y_data = [y[i[0]] for i in x_data]
y_data_train = y_data[:int(len(y_data) * .5)]
y_data_train
x_test = [a[1] for a in x_data[::-1][:int(len(x_data) * .5)]]
y_test = [a for a in y_data[::-1][:int(len(y_data) * .5)]]
x = torch.tensor(x_data_train).float() # <2>
print(x)
y = torch.tensor(y_data_train).long()
print(y)
x_test = torch.tensor(x_test).float()
print(x_test)
y_test = torch.tensor(y_test).long()
print(y_test)
class Dropout(nn.Module):
def __init__(self, p=0.5, inplace=False):
# print(p)
super(Dropout, self).__init__()
if p < 0 or p > 1:
raise ValueError("dropout probability has to be between 0 and 1, "
"but got {}".format(p))
self.p = p
self.inplace = inplace
def forward(self, input):
print(list(input.shape))
return np.random.binomial([np.ones((len(input),np.array(list(input.shape))))],1-dropout_percent)[0] * (1.0/(1-self.p))
def __repr__(self):
inplace_str = ', inplace' if self.inplace else ''
return self.__class__.__name__ + '(' \
+ 'p=' + str(self.p) \
+ inplace_str + ')'
class MyLinear(nn.Linear):
def __init__(self, in_feats, out_feats, drop_p, bias=True):
super(MyLinear, self).__init__(in_feats, out_feats, bias=bias)
self.custom_dropout = Dropout(p=drop_p)
def forward(self, input):
dropout_value = self.custom_dropout(self.weight)
return F.linear(input, dropout_value, self.bias)
my_train = data_utils.TensorDataset(x, y)
train_loader = data_utils.DataLoader(my_train, batch_size=2, shuffle=True)
my_test = data_utils.TensorDataset(x_test, y_test)
test_loader = data_utils.DataLoader(my_train, batch_size=2, shuffle=True)
# Device configuration
device = 'cpu'
print(device)
# Hyper-parameters
input_size = 2
hidden_size = 100
num_classes = 2
learning_rate = 0.0001
pred = []
# Fully connected neural network with one hidden layer
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes, p):
super(NeuralNet, self).__init__()
# self.drop_layer = nn.Dropout(p=p)
# self.drop_layer = MyLinear()
# self.fc1 = MyLinear(input_size, hidden_size, p)
self.fc1 = MyLinear(input_size, hidden_size , p)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# out = self.drop_layer(x)
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, num_classes, p=0.9).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Move tensors to the configured device
images = images.reshape(-1, 2).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
自定义的dropout实现如下:
class Dropout(nn.Module):
def __init__(self, p=0.5, inplace=False):
# print(p)
super(Dropout, self).__init__()
if p < 0 or p > 1:
raise ValueError("dropout probability has to be between 0 and 1, "
"but got {}".format(p))
self.p = p
self.inplace = inplace
def forward(self, input):
print(list(input.shape))
return np.random.binomial([np.ones((len(input),np.array(list(input.shape))))],1-dropout_percent)[0] * (1.0/(1-self.p))
def __repr__(self):
inplace_str = ', inplace' if self.inplace else ''
return self.__class__.__name__ + '(' \
+ 'p=' + str(self.p) \
+ inplace_str + ')'
class MyLinear(nn.Linear):
def __init__(self, in_feats, out_feats, drop_p, bias=True):
super(MyLinear, self).__init__(in_feats, out_feats, bias=bias)
self.custom_dropout = Dropout(p=drop_p)
def forward(self, input):
dropout_value = self.custom_dropout(self.weight)
return F.linear(input, dropout_value, self.bias)
看起来我实现了错误的dropout函数?:
np.random.binomial([np.ones((len(input),np.array(list(input.shape))))],1-dropout_percent)[0] * (1.0/(1-self.p))
如何修改以正确使用dropout?
这些文章有助于理解:
Hinton在Python中用3行代码实现的Dropout: https://iamtrask.github.io/2015/07/28/dropout/ 创建自定义的Dropout函数: https://discuss.pytorch.org/t/making-a-custom-dropout-function/14053/2