我有一个包含多个日期时间间隔(开始时间,结束时间)和值的数据框。
输入:
id start end value
1 08:00:00.000 12:00:00.000 5
2 09:00:00.000 10:00:00.000 6
2 10:00:00.000 14:00:00.000 4
1 12:00:00.000 15:00:00.000 3
expected output:
id start end value
1 08:00:00.000 09:00:00.000 5
2 09:00:00.000 10:00:00.000 6
1 10:00:00.000 12:00:00.000 5
2 12:00:00.000 14:00:00.000 4
1 14:00:00.000 15:00:00.000 3
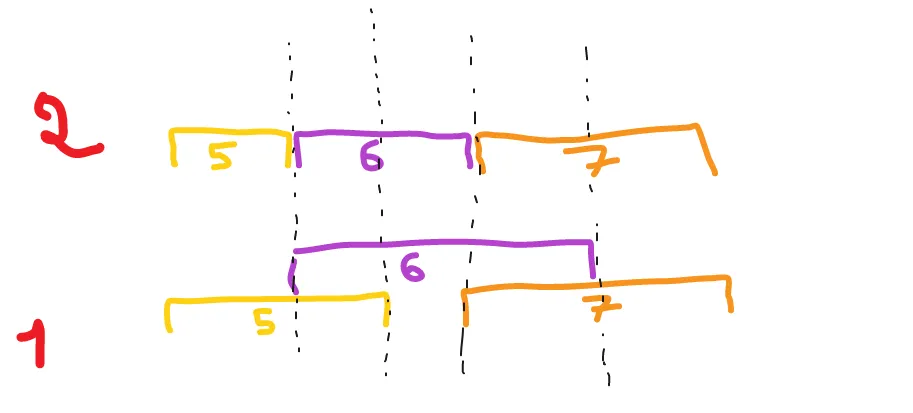
它们之间存在重叠。目标是有一系列不重叠的时间间隔。
{kind=link}
当存在重叠时,我希望保留价值最高的时间间隔。
我编写了一个循环代码,在数据框上查找重叠的时间间隔,根据条件创建新的时间间隔并删除旧的时间间隔。 我想找到一种更好的优化方法。也许是在交叉点处拆分所有时间间隔,然后在数据框上循环并基于条件删除重叠的时间间隔。
done = True
while done:
done = False
df_copy = df
for i, row in df.iterrows():
row_interval = pd.Interval(row.start, row.end)
if done:
break
for j, row_copy in row_copy.iterrows():
row_copy_interval = pd.Interval(row_copy.start, row_copy.end)
if i is not j and row_interval.overlaps(row_copy_interval):
earliest_start = np.minimum(row.start, row_copy.start)
latest_start = np.maximum(row.start, row_copy.start)
earliest_end = np.minimum(row.end, row_copy.end)
latest_end = np.maximum(row.end, row_copy.end)
if row.value > row_copy.value:
value = row.value
else:
value = row_copy.value
if row_interval == pd.Interval(earliest_start, earliest_end):
df = df.append('value': row.value, 'start': earliest_start,'end': latest_start}, ignore_index=True)
df = df.append('value': value, 'start': latest_start,'end': earliest_end}, ignore_index=True)
df = df.append('value': row_copy.value, 'start': earliest_end,'end': latest_end}, ignore_index=True)
elif row_interval == pd.Interval(earliest_start, latest_end):
...
elif row_interval == pd.Interval(latest_start, latest_end):
...
elif row_interval == pd.Interval(latest_start, earliest_end):
...
df = df.drop([i, j]).drop_duplicates()
done = True
break