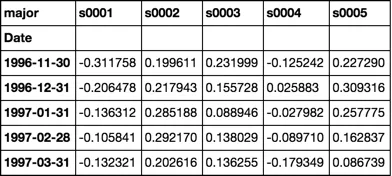
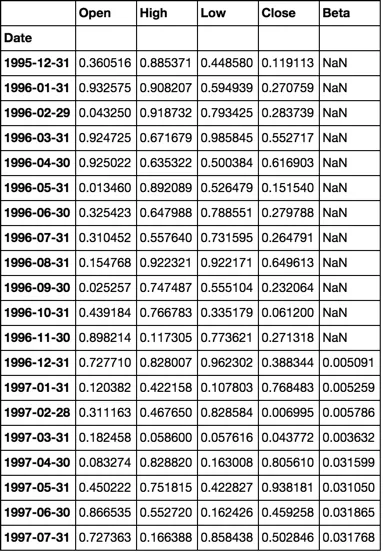
我有许多(4000+)股票数据的CSV文件(Date, Open, High, Low, Close),我将它们导入单独的Pandas数据帧中进行分析。我是 Python 的新手,想要计算每个股票的滚动12个月贝塔值。我发现了一个用于计算滚动贝塔值的 post (Python pandas calculate rolling stock beta using rolling apply to groupby object in vectorized fashion),但当在我的代码中使用时需要超过2.5小时!考虑到我可以在不到3分钟的时间内在 SQL 表格中运行完全相同的计算,这个速度太慢了。
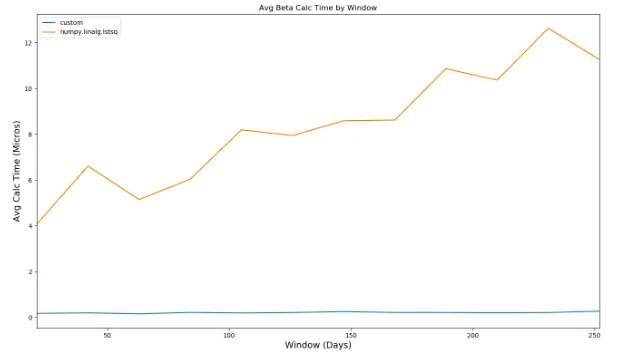
如何改善下面代码的性能以使其与 SQL 相匹配呢?我知道 Pandas / python 具备这种能力,目前我的方法是遍历每一行,但我不知道是否有任何聚合方式可以对数据帧执行滚动窗口贝塔值计算。
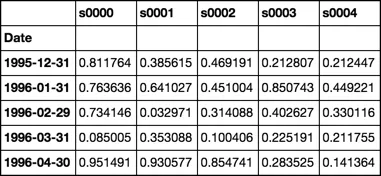
注意:将 CSV 文件加载到单独的数据帧中并计算每日回报率的前两步仅需要约20秒。所有 CSV 数据帧都存储在名为 'FilesLoaded' 的字典中,例如 'XAO'。
非常感谢您的帮助! 谢谢 :)
如何改善下面代码的性能以使其与 SQL 相匹配呢?我知道 Pandas / python 具备这种能力,目前我的方法是遍历每一行,但我不知道是否有任何聚合方式可以对数据帧执行滚动窗口贝塔值计算。
注意:将 CSV 文件加载到单独的数据帧中并计算每日回报率的前两步仅需要约20秒。所有 CSV 数据帧都存储在名为 'FilesLoaded' 的字典中,例如 'XAO'。
非常感谢您的帮助! 谢谢 :)
import pandas as pd, numpy as np
import datetime
import ntpath
pd.set_option('precision',10) #Set the Decimal Point precision to DISPLAY
start_time=datetime.datetime.now()
MarketIndex = 'XAO'
period = 250
MinBetaPeriod = period
# ***********************************************************************************************
# CALC RETURNS
# ***********************************************************************************************
for File in FilesLoaded:
FilesLoaded[File]['Return'] = FilesLoaded[File]['Close'].pct_change()
# ***********************************************************************************************
# CALC BETA
# ***********************************************************************************************
def calc_beta(df):
np_array = df.values
m = np_array[:,0] # market returns are column zero from numpy array
s = np_array[:,1] # stock returns are column one from numpy array
covariance = np.cov(s,m) # Calculate covariance between stock and market
beta = covariance[0,1]/covariance[1,1]
return beta
#Build Custom "Rolling_Apply" function
def rolling_apply(df, period, func, min_periods=None):
if min_periods is None:
min_periods = period
result = pd.Series(np.nan, index=df.index)
for i in range(1, len(df)+1):
sub_df = df.iloc[max(i-period, 0):i,:]
if len(sub_df) >= min_periods:
idx = sub_df.index[-1]
result[idx] = func(sub_df)
return result
#Create empty BETA dataframe with same index as RETURNS dataframe
df_join = pd.DataFrame(index=FilesLoaded[MarketIndex].index)
df_join['market'] = FilesLoaded[MarketIndex]['Return']
df_join['stock'] = np.nan
for File in FilesLoaded:
df_join['stock'].update(FilesLoaded[File]['Return'])
df_join = df_join.replace(np.inf, np.nan) #get rid of infinite values "inf" (SQL won't take "Inf")
df_join = df_join.replace(-np.inf, np.nan)#get rid of infinite values "inf" (SQL won't take "Inf")
df_join = df_join.fillna(0) #get rid of the NaNs in the return data
FilesLoaded[File]['Beta'] = rolling_apply(df_join[['market','stock']], period, calc_beta, min_periods = MinBetaPeriod)
# ***********************************************************************************************
# CLEAN-UP
# ***********************************************************************************************
print('Run-time: {0}'.format(datetime.datetime.now() - start_time))