希望找到适当的建模方法来满足以下要求。
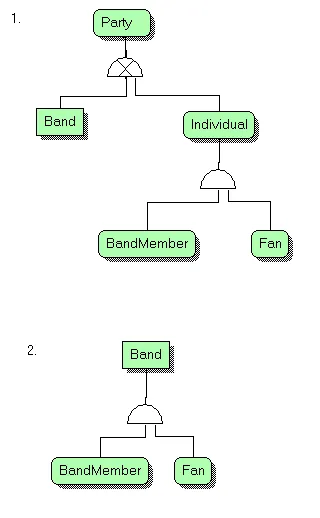
- 需要关注3种“方案”类型,即粉丝、乐队和乐队成员。
- 乐队成员将始终与一个乐队相关联,并且也可以是任何乐队的粉丝。
- 粉丝、乐队和乐队成员之间有共同点,但这3个实体也都有自己独特的属性。
- 粉丝可以成为任何乐队的粉丝或者不喜欢任何乐队。
这只是更大想法的一小部分,但它在扩展模型时产生了困惑。我认为它必须是第二个图表或其他选项,因为我不知道第一个模型中如何将乐队成员与乐队相关联。
感谢您的任何意见。
希望找到适当的建模方法来满足以下要求。
这只是更大想法的一小部分,但它在扩展模型时产生了困惑。我认为它必须是第二个图表或其他选项,因为我不知道第一个模型中如何将乐队成员与乐队相关联。
感谢您的任何意见。
即使实现了子类型,它们的实现方式也非常有限。子类型会改变超类型的角色。正确的实现非常罕见,我从未在任何地方看到过这种实现(除了我的客户的数据库实现和一些高端供应商)。
关键是,这可能看起来很“复杂”,但实际上它非常简单。
这就是Ken Downs和Chris Behrens混淆建模简单性(高度可扩展)与未建模实现(不正确和不可扩展)的地方,因为他们采用了像Martin Fowler这样的小人物提出的简单方法。不冒犯,我明白人们会喜欢并捍卫他们所知道的东西,无论那有多么有限。
请注意,每个子类型也是一个完全有效的实体(在物理上是一个表格,当我们到达那个阶段时),并且可以独立存在。
对于具有与这些子类型相关系的较低级别或事务或功能表,技巧在于使用正确的子类型(角色)。常见的错误是使用Party,然后失去了子类型或角色的意义和正确的参照完整性。
所有角色名称都是派生自Party,但这并不是使用正确角色而不是Party的有效理由。
在这里,您非常了解数据,但(没有人教过您这个),您混淆了角色和子类型。
BandMember和Fan不是Parties。他们首先是Persons(而Person是一个Party)
为了澄清这些观点,在这个概念层面上,我们需要使用实体和标识符(而不是属性),而不仅仅是实体。因此,我也提供了这一点。
在介绍模型之前,我想先指出这些问题,因为您似乎非常有兴趣学习 IDEF1X,这是建模关系数据库的标准方法,以便在将来简化您的模型。SO或任何网站都不是正式互动教育的好媒介,但我们会尽力而为。
在模型(1)中,Band不能是独立的(方形角):因为它被确定为依赖于Party;它是Party的子类型;并且它具有相同的标识符。
缺失的基数非常重要。将其放入实际上有助于解决模型问题。我不关心IDEF1X(圆圈)与IEEE(鸦脚)之间的区别,但我总是在建模过程中添加它们,并随着模型的进展不断更改它们。
Band由多个成员组成。等等。此时,规则也非常重要。事实上,建模就是建模规则。因此,纠正或调节规则是建模过程的一部分。
粉丝可以是任何乐队的歌迷,也可以不是是不合理的。如果一个Person是根本没有,那么他们是普通公众的成员,他们与任何Band都没有关系。一个普通的Person。
Fan至少与一个Band有关系。事实上,与Band有关系是将Person从该领域中带出并导致存储Fan详细信息或特定的乐队粉丝详细信息。
如果存在Fan with no Band这样的实体(即,您正在存储该实体的详细信息,与我的模型不同),请告知,我将更改模型(纸张很便宜!)。
动词短语在此阶段也很重要;不亚于我上面提到的规则和基数,它是建模过程的一部分,并且随着模型的进展需要改变/调节。您无法想象正确使用动词短语有多重要。将它们放入可能有助于您澄清子类型与角色的区别。以下是每个数据建模者都熟记于心的定义。
实体是模型中的名词
关系是动词,发生在名词之间的行动
动词短语定义这些行动(这就是为什么它们被准确地称为动词短语,这不是一个有趣的名称)。
如IDEF1X符号文件所述,对于关联表,通过它们的动词短语“through”读取到关联的另一侧的父级。
Person制作了一对多的Bands,因此是一个Member
Band由一对多的People组成,他们是Members
Person资助Band,这使他们成为Fan(不仅仅是在Fan表中拥有一行的Person)
Band依赖于是Fans的People
想出最短、最有意义的动词短语;不要使用简单化的词汇(应避免使用“包括”),这对建模者来说是一个挑战。请随意改善我提供的动词短语。
这是你的Party Data Model在实体和键级别上的IDEF1X。
如果读者不熟悉关系数据库建模标准,可能会发现我的IDEF1X符号很有用。
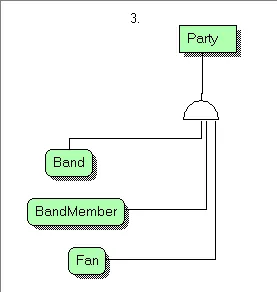
我所做的一切只是解决上述识别出来的子类型、角色和关系的基数。
当你评估第二批或交易实体时,子类型与角色的相关性将更加清晰(正如你所说,在这里我们只有标识实体)。
标识符。这值得详细说明,不仅是为了澄清模型,也因为它是使用IDEF1X标识符的一个很好的例子,以及它们所具有的强大功能。您已经在模型中指出了这一点(实线),我只是给予了全面的处理。
Person和Band是Party的子类型。他们也是Party的角色。因此,从那一点开始,我们使用PersonId和BandId,而不是PartyId(尽管它是PartyId)。
当Person扮演Member的角色时,我们使用MemberId(它是PersonId,它是PartyId)。
当Person扮演Fan的角色时,我们使用FanId(它是PersonId,它是PartyId)。
SELECT ...,
Name -- Party.Name
...
FROM Party
JOIN Fan
ON PartyId = FanId
我认为这比你想象的要简单。你有两个对象 - Band和Person,它们可以以两种不同的方式连接,即作为粉丝或成员。这是一个快速的数据库脚本,没有外键或其他任何东西:
CREATE TABLE [dbo].[XREFBandMembers](
[MemberID] [int] NOT NULL,
[BandId] [int] NOT NULL,
CONSTRAINT [PK_XREFBandMembers] PRIMARY KEY CLUSTERED
(
[MemberID] ASC,
[BandId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[XREFBandFans](
[FanId] [int] NOT NULL,
[BandId] [int] NOT NULL,
CONSTRAINT [PK_XREFBandFans] PRIMARY KEY CLUSTERED
(
[FanId] ASC,
[BandId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[People](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](100) NOT NULL,
CONSTRAINT [PK_People] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[Bands](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_Bands] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
- 两个切片。放心,我已经说过“没有抱怨,只是保留更改模型的权利”。
- 你的态度很好。我可以看出你正在努力学习方法论,这就是为什么我发布了每个要点的完整解释。
- 我认为我的回答能够激发一些寻求者是一个严肃的赞美,哇!这本身就值得在这个网站上承受负面情绪。
- 请投票(这与选择答案不同),我会得到10美分。
- PerformanceDBA