我正在学习关系模型和数据建模。
但是我对子类型有一些困惑。
我知道数据建模是一个迭代的过程,有很多不同的建模方式。
但我不知道如何在不同选项之间进行选择。
示例
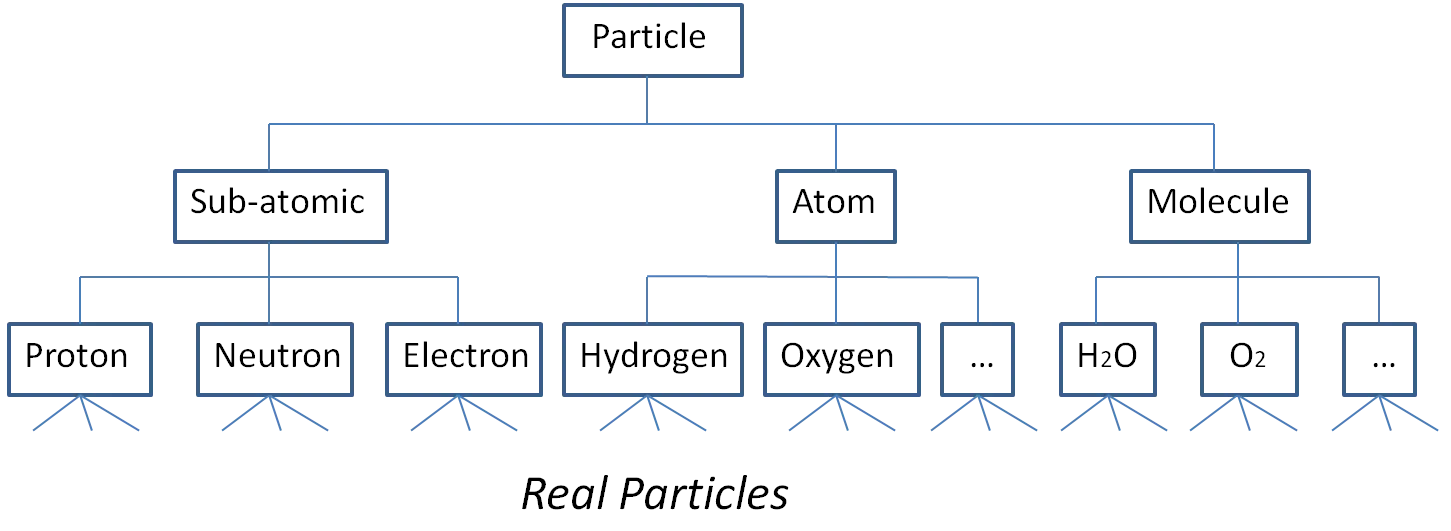
假设我们要对粒子(分子、原子、质子、中子、电子等)进行建模。
为简单起见,我们忽略夸克和其他粒子。
由于同类型的所有粒子的行为相同,因此我们不会对单个粒子进行建模。
换句话说,我们不会存储每个氢原子。
相反,我们将存储氢、氧和其他原子类型。
我们要建模的实际上是粒子类型及其之间的关系。
我随意使用“类型”这个词。
氢原子是一个实例。氢是一种类型。氢也是原子的一种类型。
是的,涉及到类型层次结构。而我们忽略了最低级别(单个粒子)。
方法
我可以想到几种建模方法。
1. 为每种事物(粒子类型)创建一个表(关系,实体)。
1.1 我想到的第一种方法。
质子 (Proton)
中子 (Neutron)
电子 (Electron)
原子 (Atom)
原子_质子 (Atom, Proton, Quantity)
原子_中子 (Atom, Neutron, Quantity)
原子_电子 (Atom, Electron, Quantity)
分子 (Molecule)
分子_原子 (Molecule, Atom, Quantity)
1.2 由于只有一种质子/中子/电子,我们可以简化它。
原子 (Atom, ProtonQuantity, NeutronQuantity, ElectronQuantity)
分子 (Molecule)
分子_原子 (Molecule, Atom, Quantity)
在这个简化模型中,关于质子的事实被遗失了。
2. 将所有事物放在一个表中,并使用关联表表示它们之间的关系。
2.1 每个关系都有一个关联表
粒子 (Particle)
Atom_Proton(Particle, Particle, ProtonQuantity)
Atom_Neutron(Particle, Particle, NeutronQuantity)
Atom_Electron(Particle, Particle, ElectronQuantity)
Molecule_Atom (Particle, Particle, AtomQuantity)
2.2 单一联想表
Particle (Particle)
ParticleComposition (Particle, Particle, Quantity)
这个简化并不会丢失任何东西,我认为这样更好。
但如果存在特定于Atom_Proton/Atom_Neutron/Atom_Electron的事实,则2.1可能更好。
2.3 结合2.1和2.2
Particle (Particle)
Atom_Proton (Particle, Particle, other attributes)
Atom_Neutron (Particle, Particle, other attributes)
Atom_Electron (Particle, Particle, other attributes)
Molecule_Atom (Particle, Particle, other attributes)
ParticleComposition(Particle, Particle, Quantity, other attributes)
在这种方法中,有关粒子组成的常见属性存储在ParticleComposition中,
而有关粒子组成的特殊属性存储在特殊表中。
3. 使用子类型表。
3.1 为基类型Particle创建一个表,并为子类型(Atom,Molecule等)创建其他表。
Particle (Particle)
Proton (Particle, other attributes)
Neutron (Particle, other attributes)
Electron (Particle, other attributes)
Atom (Particle, other attributes)
Molecule (Particle, other attributes)
Atom_Proton (Particle, Particle, ProtonQuantity)
Atom_Neutron (Particle, Particle, NeutronQuantity)
Atom_Electron (Particle, Particle, ElectronQuantity)
Molecule_Atom (Particle, Particle, AtomQuantity)
3.2 我们还可以将Atom中的Atom_XXXQuantity表合并并删除Pronton/Neutron/Electron。
Particle (Particle)
Atom (Particle, ProtonQuantity, NeutronQuantity, ElectronQuantity)
Molecule (Particle, other attributes)
分子_原子 (粒子, 粒子, 原子数量)
这个更简单,但是关于质子/中子/电子的信息像1.2一样丢失了。
3.3 我们可以改变分子_原子的名称使其更加通用。
粒子 (粒子)
原子 (粒子, 质子数量, 中子数量, 电子数量)
分子 (粒子, 其他属性)
粒子组成 (粒子, 粒子, 数量)
这看起来像2.2,有附加表格用于子类型(原子, 分子)。
似乎2.2是3.3的特例。
3.4 我们可以结合所有上述方法得到一个通用模型。
粒子 (粒子)
质子 (粒子, 其他属性)
中子 (粒子, 其他属性)
电子 (粒子, 其他属性)
原子 (粒子, 其他属性)
分子 (粒子, 其他属性)
粒子组成 (粒子, 粒子, 数量, 其他属性)
原子_质子 (粒子, 粒子, 其他属性)
原子_中子 (粒子, 粒子, 其他属性)
原子_电子 (粒子, 粒子, 其他属性)
分子_原子 (粒子, 粒子, 其他属性)
看起来原子_质子、原子_中子、原子_电子和分子_原子可以被视为粒子组成的子类型。
这种方法是最复杂的,它包含了许多表格,但每个表格都有其作用。
问题
- 以上的设计是否违反了关系模型的规则?
- 哪种方法最好?这是否取决于我们如何考虑数据?是否取决于需求?
如果取决于需求,那么我们应该首先选择最简单的设计,然后使其更通用以适应新需求吗?
尽管生成的数据模型有很多相似之处,但初始设计可能会影响表/列的命名以及键的域是不同的。- 如果我们选择为每种类型的物品使用一个表,则可以选择不兼容的键来表示Atom和Molecule,例如,对于Atom选用“原子重量”,而对于Molecule选用“分子名称”。
- 如果我们选择通用方法,则可以为所有粒子选择一个公共键。
改变键可能对系统产生更大的影响,因此从简单设计发展到通用设计可能并不容易。
你怎么看?
PS:这可能不是一个合适的例子,解决方案也可能存在问题,并且可能存在更多变化的方法,但希望您能理解要点。
如果您有更好的设计,请与我分享。
更新1
需要建模的数据是什么?
最初,我正在尝试建模粒子,因为
- 我认为它们之间存在子类型关系,这正是我要寻找的。
- 它们被人们充分理解(?)。
- 这是一个很好的例子,展示了人们如何理解世界。
以下是我脑海中的图片。
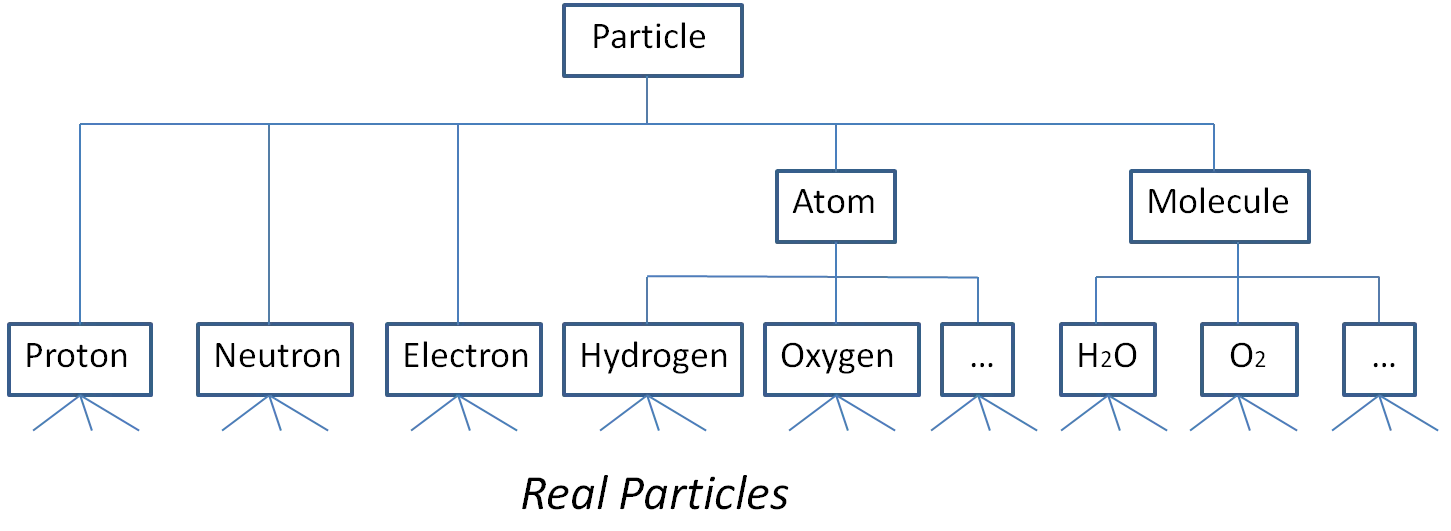
我没有清楚地表述这一点,因为我对我要建模的内容不是很清楚。
首先,我认为Atom是Proton / Neutron / Electron的父级,而Molecule是Atom的父级。
然后我意识到,这是关于组合,而不是关于子类型,也不是关于类型层次结构。
类型
我已经想了一段时间关于类型、分组和分类的问题。
以下是《SQL与关系理论》的一句话:
人们用“整数”这个名字来表示整数值的集合。 实际上,人们创造概念和名称来识别事物,将事物分组以便我们可以理解/模拟世界。那么,类型究竟是什么呢?本质上,它是一组有限的命名值─某种特定的所有可能的值的集合:例如,所有可能的整数、所有可能的字符串、所有可能的供应商编号、所有可能的XML文档、具有特定标题的所有可能关系(等等)。
质子是一组真正的质子,氢是一组氢原子,等等。 在这个意义上,真正的粒子留在类型层次结构的最低层。
我一开始试图对所有粒子进行建模,但后来遇到了以下问题: - 我想不出一个适当的键来识别每个真正的粒子; - 要将它们存储在数据库中太多了。
因此,我决定忽略真正的粒子,而是对类型进行建模。
当我们说“分子由原子组成”时,它意味着“真正的H2O分子由两个真正的氢原子和一个氧原子组成”,也意味着“任何(类型的)分子都是由(某些类型的)原子组成的”。
与其陈述有关真正粒子的每个事实,我们不如只陈述有关粒子类型的事实。 这就是我们通过分组事物和命名(类型)获得的好处。
粒子类型层次结构作为集合可以被翻译为集合定义。
第二级 - 真正粒子上面的类型:
S_proton = { p | p satisfied the definition of a proton }
S_neutron = { n | n satisfied the definition of a neutron }
S_electron = { e | e satisfied the definition of an electron }
S_hydrogen = { h | h satisfied the definition of a hydrogen }
S_oxygen = { o | o satisfied the definition of an oxygen }
S_h2o = { w | w satisfied the definition of a h2o }
S_o2 = { o | o satisfied the definition of a o2 }
更高级别
使用集合论的术语,如果 A 是 B 的子集,则类型 A 是类型 B 的子类型。
我最初认为我们可以将Atom类型定义为:
S_atom = S_hydrogen union S_oxygen union ...
然而,集合是关系,元素是元组,因此如果关系中的元组不兼容,则并集无法运行。
使用子类型表的方法解决了这个问题并建立了子集关系模型。
但在子类型方法中,Atom仍处于第二层。
高级类型定义为集合的集合。
S_atom = { S_hydrogen, S_oxygen, ... }
S_molecule = { S_h2o, S_o2, ... }
S_particle = { S_proton, S_neutron, S_electron, S_atom, S_molecule }
这意味着粒子是原子的一种类型,而氢是原子的一种类型。这样,粒子之间的关系可以在高层次上表示。
新的数据模型
4. 将类型视为类型层次结构
ParticleType (ParticleType, Name) ParticleTypeHierarchy (ParticleType, ParentType) ParticleComposition (PartileType, SubParticleType, Quantity)
示例数据:
ParticleType | ParticleType | Name | |--------------+----------| | Particle | Particle | | Proton | Proton | | Neutron | Neutron | | Electron | Electron | | Atom | Atom | | Molecule | Molecule | | H | Hydrogen | | O | Oxygen | | H2O | Water | | O2 | Oxygen |
ParticleTypeHierarchy | ParticleType | ParentType | |--------------+------------| | Proton | Particle | | Neutron | Particle | | Electron | Particle | | Atom | Particle | | Molecule | Particle | | Hydrogen | Atom | | Oxygen | Atom | | H2O | Molecule | | O2 | Molecule |
ParticleComposition | PartileType | SubParticleType | Quantity | |-------------+-----------------+----------| | H | Proton | 1 | | H | Electron | 1 | | He | Proton | 2 | | He | Neutron | 2 | | He | Electron | 2 | | H2O | H | 2 | | H2O | H | 2 | | H2O | O | 1 | | CO2 | C | 1 | | CO2 | O | 2 |
相比之下,这是子类型表方法的示例数据。
粒子 | ParticleId | ParticleName | |------------+----------------| | H | 氢 | | He | 氦 | | Li | 锂 | | Be | 铍 | | H2O | 水 | | O2 | 氧气 | | CO2 | 二氧化碳 |
分子 | MoleculeId | some_attribute | |------------+----------------| | H2O | ... | | O2 | ... | | CO2 | ... |
原子 | AtomId | ProtonQuantity | NeutronQuantity | ElectronQuantity | |--------+----------------+-----------------+------------------| | H | 1 | 0 | 1 | | He | 2 | 2 | 2 | | Li | 3 | 4 | 3 | | Be | 4 | 5 | 4 |
粒子组成 | ParticleId | ComponentId | Quantity | |------------+-------------+----------| | H2O | H | 2 | | H2O | O | 1 | | CO2 | C | 1 | | CO2 | O | 2 | | O2 | O | 2 |亚原子
这些粒子类型是由人定义的,并且人们不断定义新概念以模拟现实的新方面。
我们可以定义“亚原子”,层次结构将如下所示:
方法4可以更容易地适应这种类型层次结构的更改。
更新2
需要记录的事实
- 世界上有不同类型的粒子:质子、中子、电子、原子、分子。
- 原子由质子、中子和电子组成。
- 分子由原子组成。
- 有许多不同类型的原子:氢、氧等。
- 有许多不同类型的分子:H2O、O2等。
- 氢原子由一个质子和一个电子组成;...
- H2O分子由两个氢原子和一个氧原子组成;...
- 不同类型的粒子可能具有特殊属性,例如原子重量等。
- ...