Description
我们有一个使用Scala编写的Spark Streaming 1.5.2应用程序,从Kinesis Stream中读取JSON事件,进行一些转换/聚合,并将结果写入不同的S3前缀。当前批处理间隔为60秒,每秒处理3000-7000个事件。我们使用检查点保护我们免受聚合损失。
这个应用程序运行良好已经一段时间了,即使遇到异常和集群重新启动也能恢复。最近,我们重新编译了Spark Streaming 1.6.0的代码,只更改了build.sbt文件中的库依赖项。在Spark 1.6.0集群中运行代码数小时后,我们注意到以下情况:
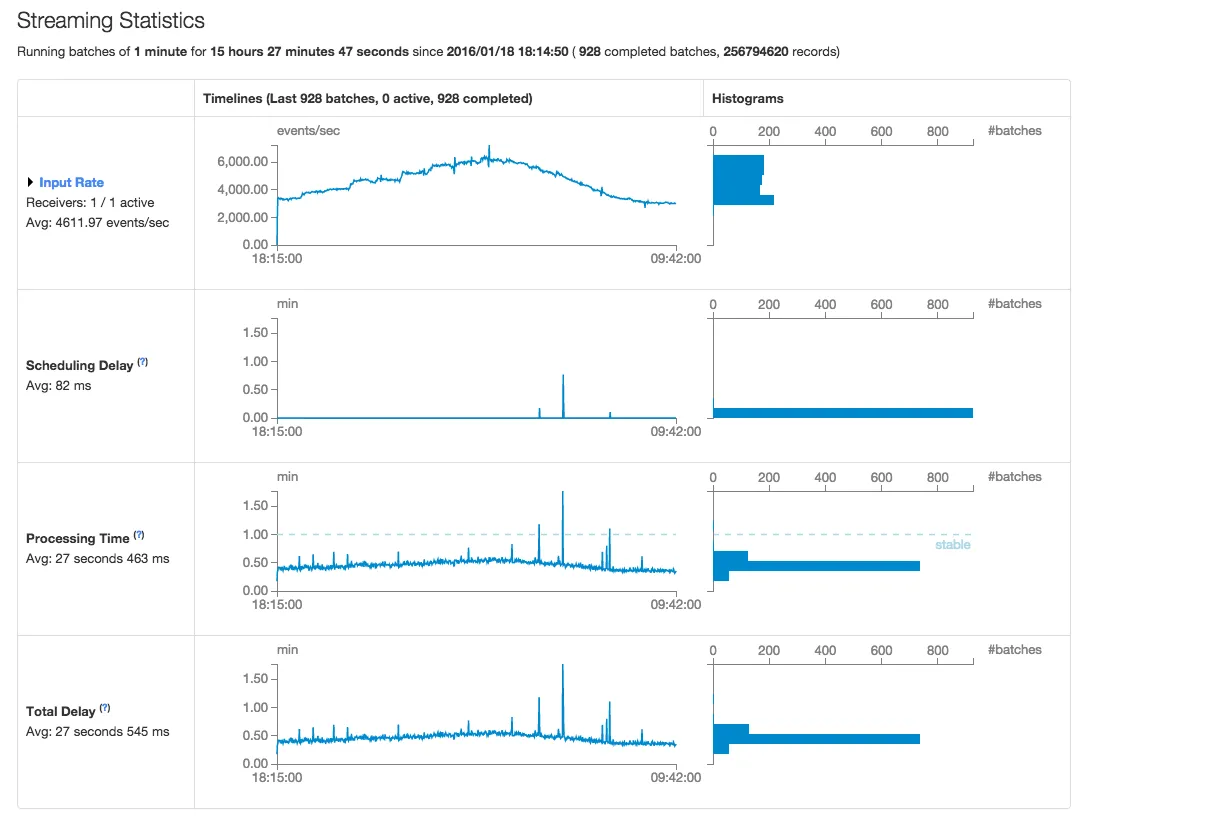
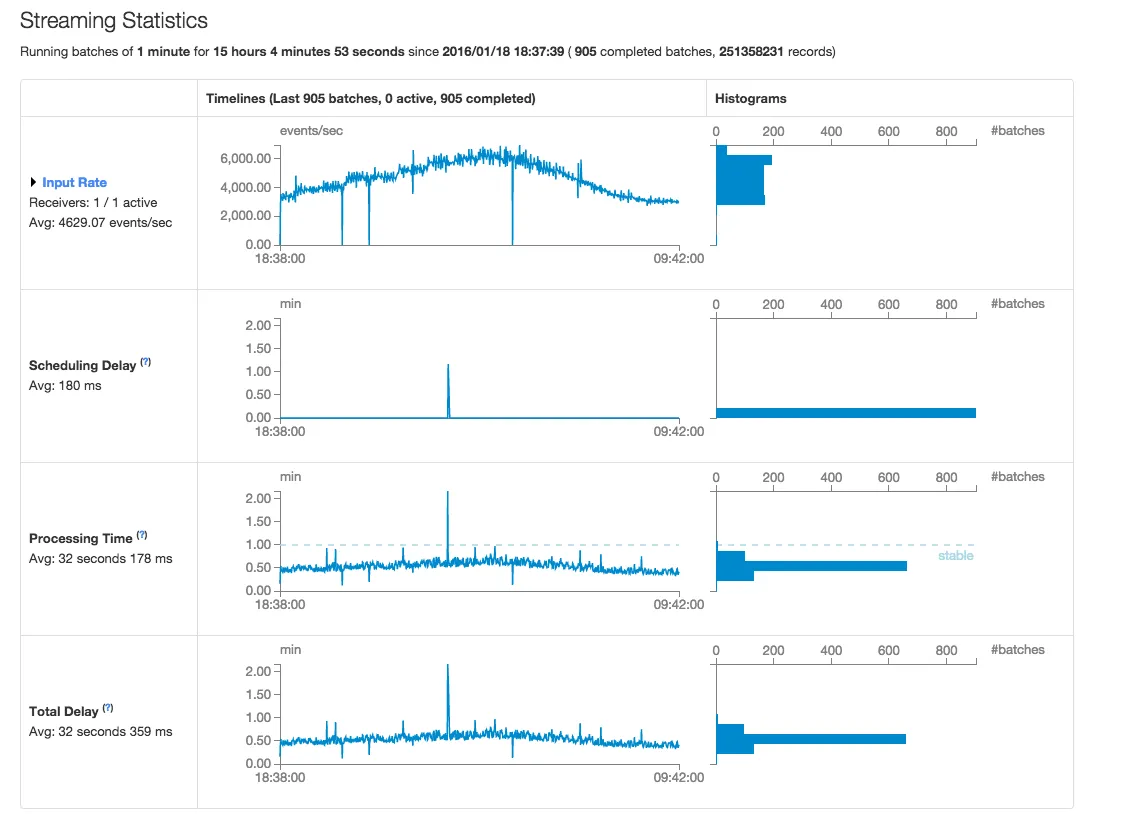
- “输入速率”和“处理时间”的波动性显著增加(请参见下面的截图)。
- 每隔几个小时,会出现“Exception thrown while writing record: BlockAdditionEvent……to the WriteAheadLog。java.util.concurrent.TimeoutException:Futures timed out after [5000 milliseconds]”异常(请参见下面的完整堆栈跟踪),与特定批次(分钟)的事件下降到0有关。
经过一些挖掘,我认为第二个问题看起来与这个Pull Request有关。PR的最初目标是:“当使用S3作为WALs目录时,写入时间太长。当多个接收器向ReceiverTracker发送AddBlock事件时,驱动程序很容易被阻塞。该PR在ReceivedBlockTracker中添加了事件批处理功能,以便接收器不会被驱动程序阻塞太长时间。
我们在Spark 1.5.2中将检查点保存在S3中,没有性能/可靠性问题。我们已经在S3和本地NAS上测试了Spark 1.6.0中的检查点,并出现了相同的异常。看起来当批处理检查点需要超过5秒时,就会出现此异常,我们已经检查了该批次的事件永久丢失。
Questions
预计在Spark Streaming 1.6.0中“输入速率”和“处理时间”的波动性增加吗?是否有任何已知的改进方式?
除了以下两种方法之外,您是否知道任何解决方法?:
1)确保检查点汇写入所有文件的时间少于5秒。根据我的经验,即使对于小批量,也无法保证在S3上做到这一点。对于本地NAS,这取决于谁负责基础架构(与云提供商难以实现)。
2)增加spark.streaming.driver.writeAheadLog.batchingTimeout属性值。
您是否期望在描述的情况下丢失任何事件?我认为,如果批处理检查点失败,则分片/接收器序列号不会增加,并将在稍后重试。
Spark 1.5.2 统计信息 - 屏幕截图
Spark 1.6.0 统计信息 - 屏幕截图
完整的堆栈跟踪
16/01/19 03:25:03 WARN ReceivedBlockTracker: Exception thrown while writing record: BlockAdditionEvent(ReceivedBlockInfo(0,Some(3521),Some(SequenceNumberRanges(SequenceNumberRange(StreamEventsPRD,shardId-000000000003,49558087746891612304997255299934807015508295035511636018,49558087746891612304997255303224294170679701088606617650), SequenceNumberRange(StreamEventsPRD,shardId-000000000004,49558087949939897337618579003482122196174788079896232002,49558087949939897337618579006984380295598368799020023874), SequenceNumberRange(StreamEventsPRD,shardId-000000000001,49558087735072217349776025034858012188384702720257294354,49558087735072217349776025038332464993957147037082320914), SequenceNumberRange(StreamEventsPRD,shardId-000000000009,49558088270111696152922722880993488801473174525649617042,49558088270111696152922722884455852348849472550727581842), SequenceNumberRange(StreamEventsPRD,shardId-000000000000,49558087841379869711171505550483827793283335010434154498,49558087841379869711171505554030816148032657077741551618), SequenceNumberRange(StreamEventsPRD,shardId-000000000002,49558087853556076589569225785774419228345486684446523426,49558087853556076589569225789389107428993227916817989666))),BlockManagerBasedStoreResult(input-0-1453142312126,Some(3521)))) to the WriteAheadLog.
java.util.concurrent.TimeoutException: Futures timed out after [5000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)
at scala.concurrent.Await$.result(package.scala:107)
at org.apache.spark.streaming.util.BatchedWriteAheadLog.write(BatchedWriteAheadLog.scala:81)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.writeToLog(ReceivedBlockTracker.scala:232)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.addBlock(ReceivedBlockTracker.scala:87)
at org.apache.spark.streaming.scheduler.ReceiverTracker.org$apache$spark$streaming$scheduler$ReceiverTracker$$addBlock(ReceiverTracker.scala:321)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1$$anonfun$run$1.apply$mcV$sp(ReceiverTracker.scala:500)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1230)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1.run(ReceiverTracker.scala:498)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
源代码提取
...
// Function to create a new StreamingContext and set it up
def setupContext(): StreamingContext = {
...
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
// Create a Kinesis DStream
val data = KinesisUtils.createStream(ssc,
kinesisAppName, kinesisStreamName,
kinesisEndpointUrl, RegionUtils.getRegionByEndpoint(kinesisEndpointUrl).getName(),
InitialPositionInStream.LATEST, Seconds(kinesisCheckpointIntervalSeconds),
StorageLevel.MEMORY_AND_DISK_SER_2, awsAccessKeyId, awsSecretKey)
...
ssc.checkpoint(checkpointDir)
ssc
}
// Get or create a streaming context.
val ssc = StreamingContext.getActiveOrCreate(checkpointDir, setupContext)
ssc.start()
ssc.awaitTermination()