我在MATLAB中有两个三维的
对于每个
例如,如果
我目前正在使用以下例程来执行此操作:
uint16(GPU)数组A和B,它们的第二、第三维度相同。例如,size(A,1)= 300000,size(B,1)= 2000 ,size(A,2)= size(B,2)= 20 ,且size(A,3)= size(B,3)= 100 ,这可以让您大致了解其数量级。实际上,size(A,3)= size(B,3)非常大,约为 1 000 000 ,但是这些数组以沿第三维切割成的小块外部存储。重点是,有一个非常长的循环沿第三个维度(cfg.MWE如下),因此需要进一步优化其中的代码(如果可能)。此外,可以假设A和B的值远低于65535 ,但仍然有数百个不同的值。对于每个
i,j和d,行A(i:,:,d)和B(j:,:,d)表示相同大小的多重集合,并且我需要找到它们的最大公共子多重集(multisubset?)的大小,即它们的交集大小作为多重集合。此外,可以假设B的行已排序。例如,如果
[2 3 2 1 4 5 5 5 6 7]和[1 2 2 3 5 5 7 8 9 11]是两个这样的多重集合,则它们的多重集合交集是[1 2 2 3 5 5 7],其大小为7(作为一个多重集合,有7个元素)。我目前正在使用以下例程来执行此操作:
s = 300000; % 1st dim. of A
n = 2000; % 1st dim. of B
c = 10; % 2nd dim. of A and B
depth = 10; % 3rd dim. of A and B (corresponds to a batch of size 10 of A and B along the 3rd dim.)
N = 100; % upper bound on the possible values of A and B
A = randi(N,s,c,depth,'uint16','gpuArray');
B = randi(N,n,c,depth,'uint16','gpuArray');
Sizes_of_multiset_intersections = zeros(s,n,depth,'uint8'); % too big to fit in GPU memory together with A and B
for d=1:depth
A_slice = A(:,:,d);
B_slice = B(:,:,d);
unique_B_values = permute(unique(B_slice),[3 2 1]); % B is smaller than A
% compute counts of the unique B-values for each multiset:
A_values_counts = permute(sum(uint8(A_slice==unique_B_values),2,'native'),[1 3 2]);
B_values_counts = permute(sum(uint8(B_slice==unique_B_values),2,'native'),[1 3 2]);
% compute the count of each unique B-value in the intersection:
Sizes_of_multiset_intersections_tmp = gpuArray.zeros(s,n,'uint8');
for i=1:n
Sizes_of_multiset_intersections_tmp(:,i) = sum(min(A_values_counts,B_values_counts(i,:)),2,'native');
end
Sizes_of_multiset_intersections(:,:,d) = gather(Sizes_of_multiset_intersections_tmp);
end
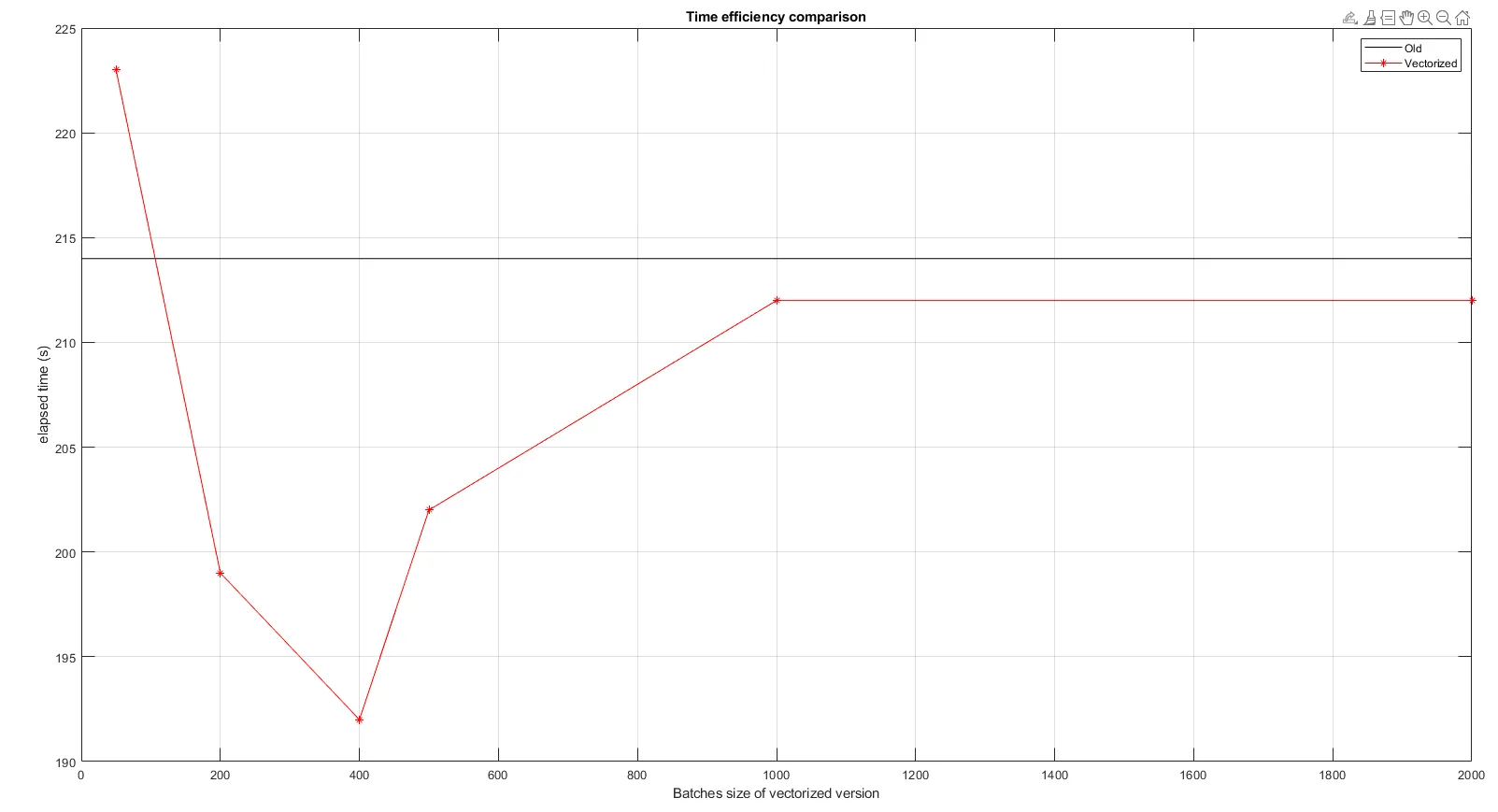
可以很容易地调整上述代码,以便沿第三维而不是d=1:depth(即大小为1的批)分批计算结果,但代价是需要更大的unique_B_values向量。
由于depth维度很大(即使在沿其进行分批处理时也是如此),我对外部循环内部的代码的更快替代方法感兴趣。因此,我的问题是:有没有一种更快(例如更好的矢量化)的方式来计算等大小的多重集合交集的大小?
intersect函数吗? - Ander Biguri[1 1]。换句话说,有限多重集的交集就是它们作为集合的交集,但是要考虑到每个多重集的重复次数,由每个多重集的最小重复次数给出。 - M.G.intersect,但由于几个原因它似乎不太适用。首先,它适用于集合,但不适用于多重集合,它仅返回集合理论上的交集,因此我仍然需要找到其他方法来计算重复次数。其次,更重要的是,它将不得不将A中的每一行与B中的每一行进行比较。我的当前代码比这更快,因为它通过向量化将整个A切片(矩阵)与B行进行比较(同时还要处理重复次数),即少了一个循环。我不知道如何避免使用intersect的额外循环。 - M.G.histc方法。注意histc可以使用可选的维度,而较新的histcounts则不行。 - beaker