我有一个DataFrame,其中包含以下数据。每一行代表一部电视剧中出现的单词。如果一个单词在一集中出现了3次,则pandas dataframe将有3行。现在我需要过滤一个单词列表,只获取出现2次或更多次的单词。我可以通过
通过groupby,我只会得到唯一的条目和计数,但我需要条目重复出现与其在对话中出现的次数相同。是否有一种一行代码就能实现这个功能?
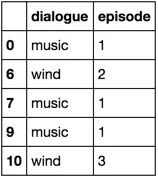
这里理想情况下应该得到:
因为这两个单词出现了2次或更多次,所以这些是唯一的两个单词。
groupby来实现,但是如果一个单词出现了2(或者说3、4或5)次,我需要它重复两次(3、4或5次)。通过groupby,我只会得到唯一的条目和计数,但我需要条目重复出现与其在对话中出现的次数相同。是否有一种一行代码就能实现这个功能?
dialogue episode
0 music 1
1 corrections 1
2 somnath 1
3 yadav 5
4 join 2
5 instagram 1
6 wind 2
7 music 1
8 whimpering 2
9 music 1
10 wind 3
这里理想情况下应该得到:
dialogue episode
0 music 1
6 wind 2
7 music 1
9 music 1
10 wind 3
因为这两个单词出现了2次或更多次,所以这些是唯一的两个单词。