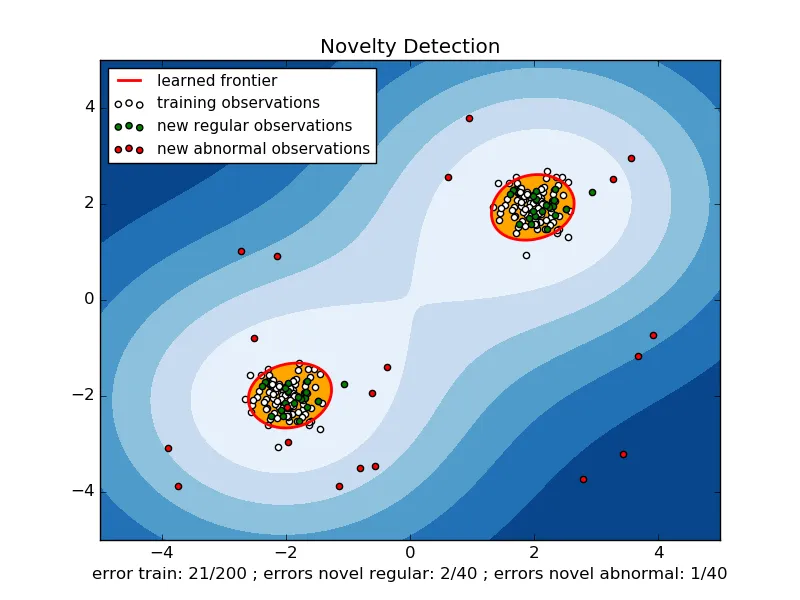
我需要一个机器学习算法,满足以下要求:
正训练数据:
- 训练数据是一组特征向量,全部属于同一“正”类(我无法生成负的数据样本)。
- 测试数据是一些可能属于正类的特征向量,也可能不属于正类。
- 预测结果应该是连续的值,表示与正样本之间的“距离”(例如,0表示测试样本明显属于正类,1表示它明显为负,但0.3表示它有一定的正性)。
正训练数据:
- (0,1)、(0,2)、(0,3)
- (0,10)应该是一个异常数据,但不是明显的异常;
- (1,0)应该是一个异常数据,但比(0,10)的“等级”更高;
- (1,10)应该是一个异常数据,且具有更高的异常“等级”。