我有两个数据框,需要使用第一个数据框将新列添加到第二个数据框,如果第一个数据框中存在,则为TRUE,否则为FALSE。
第一个数据框包含USA大学城的州和地区名称。
State RegionName
0 Alabama Auburn
1 Alabama Florence
2 Alabama Jacksonville
3 Illinois Chicago
第二个数据框显示每个季度的增长率,索引为州和地区名称。
2008q3 2008q4
State RegionName
Alabama Jacksonville 499766.666667 487933.333333
California Los Angeles 469500.000000 443966.666667
Illinois Chicago 232000.000000 227033.333333
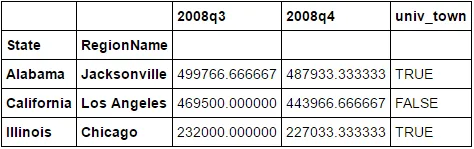
所以输出的数据框将会是:
2008q3 2008q4 univ_town
State RegionName
Alabama Jacksonville 499766.666667 487933.333333 TRUE
California Los Angeles 469500.000000 443966.666667 FALSE
Illinois Chicago 232000.000000 227033.333333 TRUE
非常感谢任何帮助。