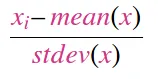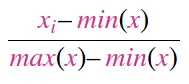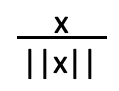我已经四处寻找,但仍找不到我想要的东西。基本上,MNIST数据集中的图像具有[0,255]范围内的像素值。人们通常建议执行以下操作:
- 将数据缩放到
[0,1]范围内。 - 对数据进行标准化,使其具有零均值和单位标准差
(data-mean) / std。
不幸的是,没有人展示如何同时执行这两个操作。他们都会减去0.1307的均值并除以0.3081的标准差。这些值基本上是数据集的平均值和标准差除以255得出的结果:
from torchvision.datasets import MNIST
import torchvision.transforms as transforms
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
print('Min Pixel Value: {} \nMax Pixel Value: {}'.format(trainset.data.min(), trainset.data.max()))
print('Mean Pixel Value {} \nPixel Values Std: {}'.format(trainset.data.float().mean(), trainset.data.float().std()))
print('Scaled Mean Pixel Value {} \nScaled Pixel Values Std: {}'.format(trainset.data.float().mean() / 255, trainset.data.float().std() / 255))
这将输出以下内容
Min Pixel Value: 0
Max Pixel Value: 255
Mean Pixel Value 33.31002426147461
Pixel Values Std: 78.56748962402344
Scaled Mean: 0.13062754273414612
Scaled Std: 0.30810779333114624
然而,这样做显然没有实现上述任何一个目标!得到的数据 1) 不会在 [0, 1] 范围内,并且其均值不是 0 或标准差不是 1。实际上我们在做的是:
[data - (mean / 255)] / (std / 255)
与下面的方法非常不同
[(scaled_data) - (mean/255)] / (std/255)
其中 scaled_data 就是 data / 255。