您可以将开始时间和结束时间列都转换为日期时间格式。然后计算时间差。最后,将时间差转换为小时差(将秒数除以3600):
df['Hours_s'] = pd.to_datetime(df['Hour Start'], format='%H' )
df['Hours_e'] = pd.to_datetime(df['Hour End'], format='%H' )
df['delta'] = df['Hours_e']-df['Hours_s']
df["count"] = df["delta"].apply(lambda x: x.seconds//3600)
输出:
ID Hour_Start Hour_End count
0 5 6 1
1 9 9 0
2 13 15 2
3 15 19 4
4 20 0 4
5 23 2 3
更新:
final_tab = pd.DataFrame({"Hour": range(0,24), "Count": [0]*24})
for i, row in df.iterrows():
if row["delta"].days != 0:
final_tab.iloc[row["Hour Start"]:24,1] =final_tab.iloc[row["Hour Start"]:24,1] +1
final_tab.iloc[0:row["Hour End"]+1,1] =final_tab.iloc[0:row["Hour End"]+1,1] +1
else:
final_tab.iloc[row["Hour Start"]:row["Hour Start"]+row["count"],1] = final_tab.iloc[row["Hour Start"]:row["Hour Start"]+row["count"],1] + 1
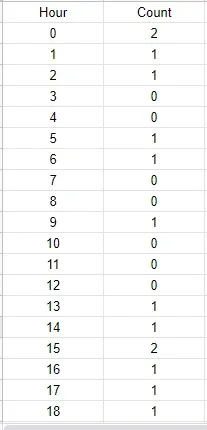
输出:
print(final_tab)
Hour Count
0 0 2
1 1 1
2 2 1
3 3 0
4 4 0
5 5 1
6 6 1
7 7 0
8 8 0
9 9 1
10 10 0
11 11 0
12 12 0
13 13 1
14 14 1
15 15 2
16 16 1
17 17 1
18 18 1
19 19 1
20 20 1
21 21 1
22 22 1
23 23 2