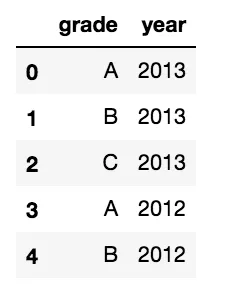
我有一个包含多个分类变量的Pandas DataFrame。例如:
import pandas as pd
d = {'grade':['A','B','C','A','B'],
'year':['2013','2013','2013','2012','2012']}
df = pd.DataFrame(d)
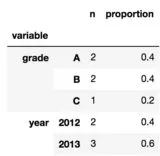
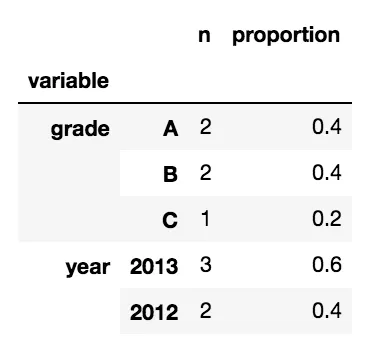
我希望将其转换为MultiIndex DataFrame,其具有以下属性:
- 第一级索引是变量名称(例如'grade')
- 第二级索引是变量内的级别(例如'A'、'B'、'C')
- 一个列包含'n',表示该级别出现的次数
- 第二个列包含'proportion',表示该级别所代表的比例。
例如:
是否有人能够提供创建此MultiIndex DataFrame的方法?