在使用Python编程语言中,使用 map() 函数和列表推导式有没有具体的优势?它们哪个更高效或被认为更符合 Python 的编程风格呢?
列表推导式 vs map函数
961
- TimothyAWiseman
4
16请注意,PyLint会警告您如果使用map而不是列表推导式,请参见message W0141。 - lumbric
5@lumbric,我不确定,但只有在使用lambda函数时,它才起作用。 - 0xc0de
8我制作了一个关于列表推导式和map函数的17分钟教程,如果有人觉得有用的话可以参考一下 - https://www.youtube.com/watch?v=hNW6Tbp59HQ - Brendan Metcalfe
YouTube视频的标题是“Python - 列表推导式 vs map函数教程(速度,lambda,历史,示例)”。 - Peter Mortensen
14个回答
844
map在某些情况下可能微观上更快(当您不是为了目的而制作lambda,而是在map和list comprehension中使用相同的函数时)。列表推导式在其他情况下可能更快,并且大多数(但不是全部)Pythonistas认为它们更直接和更清晰。
一个例子是当使用完全相同的函数时,map具有微小的速度优势:
$ python -m timeit -s'xs=range(10)' 'map(hex, xs)'
100000 loops, best of 3: 4.86 usec per loop
$ python -m timeit -s'xs=range(10)' '[hex(x) for x in xs]'
100000 loops, best of 3: 5.58 usec per loop
当map需要一个lambda函数时,性能比较完全反转的示例:
$ python -m timeit -s'xs=range(10)' 'map(lambda x: x+2, xs)'
100000 loops, best of 3: 4.24 usec per loop
$ python -m timeit -s'xs=range(10)' '[x+2 for x in xs]'
100000 loops, best of 3: 2.32 usec per loop
- Alex Martelli
22
70是的,实际上我们公司内部的Python风格指南明确推荐使用列表推导式而不是map和filter函数(甚至没有提到在某些情况下map可以带来微小但可测量的性能提升;-)。 - Alex Martelli
57不是要贬低Alex的无限风格得分,但有时候对我来说使用map看起来更容易阅读:data = map(str, some_list_of_objects)。还有一些其他的,比如operator.attrgetter、operator.itemgetter等等。 - Gregg Lind
80
map(operator.attrgetter('foo'), objs) 比 [o.foo for o in objs] 更易读?! - Alex Martelli70我更喜欢不使用不必要的名称,比如这里的“o”,你的例子说明了原因。 - Reid Barton
37我认为@GreggLind的'str()'例子是有道理的。 - Eric O. Lebigot
显示剩余17条评论
596
案例
- 常见情况:几乎总是需要在Python中使用列表推导,因为对于阅读你的代码的初学者程序员来说,它更容易理解你正在做什么(这不适用于其他语言,其中可能适用其他惯用语)。 对于Python程序员来说,即使更加明显,因为列表推导是Python迭代的事实标准; 它们是预期的。
- 不常见情况:但是,如果您已经定义了一个函数,则通常可以使用
map,尽管这被认为是“不符合Python风格”。例如,map(sum,myLists)比[sum(x)for x in myLists]更优雅/简洁。您将获得不必为迭代制作虚拟变量(例如sum(x)for x ...或sum(_)for _ ...或sum(readableName)for readableName ...)的优雅之处。您必须输入两遍。同样的论点也适用于filter和reduce以及itertools模块中的任何内容:如果您已经有一个方便的函数,则可以进行一些函数式编程。这在某些情况下增加了可读性,在其他情况下减少了可读性(例如初学者程序员,多个参数)...但是您的代码的可读性高度依赖于您的注释。 - 几乎从不:您可能希望在进行函数式编程时将
map函数用作纯抽象函数,其中您正在映射map,或对map进行柯里化,或以其他方式受益于讨论map作为一个函数。例如,在Haskell中,称为fmap的functor接口通用地映射到任何数据结构。这在Python中非常罕见,因为Python语法迫使您使用生成器样式来讨论迭代; 你无法轻松泛化它。(有时候好,有时候坏。) 你可能会找到一些罕见的Python示例,其中map(f,* lists)是可以做的合理的事情。我能想到的最接近的例子是sumEach = partial(map,sum),这是一个非常粗略等价的单行代码:
def sumEach(myLists):
return [sum(_) for _ in myLists]
- 使用for循环:当然你也可以直接使用for循环。虽然从函数式编程的角度看不够优雅,但有时对于命令式编程语言如Python来说,使用非局部变量可以让代码更清晰,因为人们习惯用这种方式阅读代码。使用for循环,在你只是进行任何不涉及构建列表的复杂操作(例如求和或创建树等)时,通常是最有效率的,至少在内存方面是这样(并不一定在时间方面,除非出现某些罕见的垃圾回收问题,最坏情况下可能会有一个常数因子)。
"Python风格"
我不喜欢“pythonic”这个词,因为我不认为Pythonic总是优雅的。尽管如此,像map和filter以及类似的函数(如非常有用的itertools模块)在风格上可能被认为不够Pythonic。
懒惰求值
就效率而言,像大多数函数式编程结构一样,map可以是惰性的,实际上在Python中是惰性的。这意味着你可以在Python3中执行以下操作,而你的计算机不会耗尽内存并丢失所有未保存的数据:
>>> map(str, range(10**100))
<map object at 0x2201d50>
试着使用列表推导式实现:
>>> [str(n) for n in range(10**100)]
# DO NOT TRY THIS AT HOME OR YOU WILL BE SAD #
需要注意的是,列表推导式本质上也是惰性求值的,但是Python选择将它们实现为非惰性的。尽管如此,Python仍然支持生成器表达式形式的惰性列表推导式,如下所示:
>>> (str(n) for n in range(10**100))
<generator object <genexpr> at 0xacbdef>
[...]语法基本上看作是将生成器表达式传递给列表构造函数,例如list(x for x in range(5))。
简单的人为示例from operator import neg
print({x:x**2 for x in map(neg,range(5))})
print({x:x**2 for x in [-y for y in range(5)]})
print({x:x**2 for x in (-y for y in range(5))})
[...]通常使事情变得明显,特别是当混杂在括号中时。另一方面,有时您最终会变得冗长,例如键入[x for x in ...。只要保持您的迭代器变量短,如果不缩进代码,则列表综合通常更清晰。但您始终可以缩进您的代码。print(
{x:x**2 for x in (-y for y in range(5))}
)
或者将事情分开:
rangeNeg5 = (-y for y in range(5))
print(
{x:x**2 for x in rangeNeg5}
)
Python3的效率比较
map现在是惰性的:
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=map(f,xs)'
1000000 loops, best of 3: 0.336 usec per loop ^^^^^^^^^
map在Python3中(以及在Python2或Python3中的生成器表达式)将避免计算它们的值,直到必要的最后一刻。通常情况下,这通常比使用map带来的任何开销更有利。缺点是,与大多数函数式语言相比,Python中非常有限:只有在按顺序访问数据时才能获得此优势,因为Python生成器表达式只能按顺序计算x [0],x [1],x [2],...。然而,假设我们有一个预制的函数
f想要map,并且我们通过立即使用list(...) 强制求值来忽略了map的懒惰性。我们会得到一些非常有趣的结果:% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=list(map(f,xs))'
10000 loops, best of 3: 165/124/135 usec per loop ^^^^^^^^^^^^^^^
for list(<map object>)
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=[f(x) for x in xs]'
10000 loops, best of 3: 181/118/123 usec per loop ^^^^^^^^^^^^^^^^^^
for list(<generator>), probably optimized
% python3 -mtimeit -s 'xs=range(1000)' 'f=lambda x:x' 'z=list(f(x) for x in xs)'
1000 loops, best of 3: 215/150/150 usec per loop ^^^^^^^^^^^^^^^^^^^^^^
for list(<generator>)
结果的形式为AAA/BBB/CCC,其中A是在约2010年的Intel工作站上使用Python 3.?.?执行的,而B和C是在约2013年的AMD工作站上使用Python 3.2.1执行的,具有非常不同的硬件。结果似乎是map和列表推导在性能上可比,最受其他随机因素的影响。我们唯一可以确定的是,奇怪的是,虽然我们期望列表推导 [...] 的性能优于生成器表达式 (...),但map 比生成器表达式(假设所有值都被评估/使用)更有效率。
需要意识到这些测试假定一个非常简单的函数(恒等函数)。但这没关系,因为如果函数复杂,那么性能开销将与程序中的其他因素相比微不足道。 (仍然测试其他简单事物,如f=lambda x:x+x可能很有趣)
如果你擅长阅读Python汇编代码,你可以使用dis模块查看幕后发生的情况:
>>> listComp = compile('[f(x) for x in xs]', 'listComp', 'eval')
>>> dis.dis(listComp)
1 0 LOAD_CONST 0 (<code object <listcomp> at 0x2511a48, file "listComp", line 1>)
3 MAKE_FUNCTION 0
6 LOAD_NAME 0 (xs)
9 GET_ITER
10 CALL_FUNCTION 1
13 RETURN_VALUE
>>> listComp.co_consts
(<code object <listcomp> at 0x2511a48, file "listComp", line 1>,)
>>> dis.dis(listComp.co_consts[0])
1 0 BUILD_LIST 0
3 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 18 (to 27)
9 STORE_FAST 1 (x)
12 LOAD_GLOBAL 0 (f)
15 LOAD_FAST 1 (x)
18 CALL_FUNCTION 1
21 LIST_APPEND 2
24 JUMP_ABSOLUTE 6
>> 27 RETURN_VALUE
>>> listComp2 = compile('list(f(x) for x in xs)', 'listComp2', 'eval')
>>> dis.dis(listComp2)
1 0 LOAD_NAME 0 (list)
3 LOAD_CONST 0 (<code object <genexpr> at 0x255bc68, file "listComp2", line 1>)
6 MAKE_FUNCTION 0
9 LOAD_NAME 1 (xs)
12 GET_ITER
13 CALL_FUNCTION 1
16 CALL_FUNCTION 1
19 RETURN_VALUE
>>> listComp2.co_consts
(<code object <genexpr> at 0x255bc68, file "listComp2", line 1>,)
>>> dis.dis(listComp2.co_consts[0])
1 0 LOAD_FAST 0 (.0)
>> 3 FOR_ITER 17 (to 23)
6 STORE_FAST 1 (x)
9 LOAD_GLOBAL 0 (f)
12 LOAD_FAST 1 (x)
15 CALL_FUNCTION 1
18 YIELD_VALUE
19 POP_TOP
20 JUMP_ABSOLUTE 3
>> 23 LOAD_CONST 0 (None)
26 RETURN_VALUE
>>> evalledMap = compile('list(map(f,xs))', 'evalledMap', 'eval')
>>> dis.dis(evalledMap)
1 0 LOAD_NAME 0 (list)
3 LOAD_NAME 1 (map)
6 LOAD_NAME 2 (f)
9 LOAD_NAME 3 (xs)
12 CALL_FUNCTION 2
15 CALL_FUNCTION 1
18 RETURN_VALUE
使用[...]语法比使用list(...)更好。不幸的是,map类在反汇编时有点难以理解,但我们可以通过速度测试来解决。
- ninjagecko
6
5非常有用的itertools模块在风格上可能被认为不符合Python的规范。嗯,我也不喜欢“Pythonic”这个术语,所以在某种意义上我不在意它的含义,但我认为根据“Pythonicness”的标准,内置函数
map和filter以及标准库中的itertools被认为是本质上不好的风格是不公平的。除非GvR实际上说过它们要么是一个可怕的错误,要么仅仅是为了性能而存在,否则如果“Pythonicness”确实是这样说的,那么唯一自然的结论就是把它当作无聊的东西忘掉;-) - Steve Jessop11@SteveJessop:实际上,Guido认为在Python 3中放弃
map/filter是一个好主意,只有其他Python程序员的反叛行动才让它们留在内置命名空间中(而reduce则被移动到了functools)。我个人不同意(如果使用预定义的特别是内置函数,则map和filter很好,只要不需要使用lambda),但是GvR多年来一直称它们不符合 Pythonic。 - ShadowRanger@ShadowRanger:没错,但GvR是否曾计划删除
itertools?我引用这个答案的部分是让我感到困惑的主要声明。我不知道在他理想的世界中,map和filter是否会移动到itertools(或functools),或者完全消失,但无论哪种情况,一旦有人说itertools在其整体上不符合Python风格,那么我真的不知道“Pythonic”应该意味着什么,但我认为它不可能与“GvR建议人们使用的东西”相似。 - Steve Jessop3@SteveJessop: 我只讨论
map/filter,没有涉及到 itertools。函数式编程在Python中是很符合规范的(itertools、functools和operator都是专为函数式编程设计的,我经常在Python中使用函数式语法),而且 itertools 提供了一些很难自己实现的功能。问题在于 map 和 filter 与生成器表达式重复,这让 Guido 讨厌它们。itertools 一直以来都是很好的。 - ShadowRanger感谢您的详细解释。当函数没有输出时(例如在原地更改数组值),哪种方法更快? - shz
我想在这个非常完整而且现在也有点古老的答案中补充一个额外的观点,那就是在我的看法中,_列表_推导式总是比
list(map(foo, x))更可取。自从Python 3以后,如果你需要一个列表而不是生成器,我认为在可读性方面,map、filter和类似的函数都不如列表推导式。至于生成器推导式的其余部分,则没有问题。 - Puff110
Python 2: 使用map和filter代替列表推导式。
即使它们不是"Pythonic",你仍应该更喜欢使用它们的一个客观原因是:
它们需要将函数/lambda作为参数,这会引入新的作用域。
我曾经多次因此受挫:
for x, y in somePoints:
# (several lines of code here)
squared = [x ** 2 for x in numbers]
# Oops, x was silently overwritten!
但是,如果我说:
for x, y in somePoints:
# (several lines of code here)
squared = map(lambda x: x ** 2, numbers)
如果一切顺利的话,那就好了。
你可以说我在同一个作用域中使用相同的变量名是傻瓜行为。
但事实并非如此。这段代码最初没问题——两个 x 不在同一个作用域。
只有在我将内部块移动到代码的不同部分后(即在维护期间出现问题而非开发期间),问题才出现了,并且我没有预料到它。
没错,如果你从未犯过这个错误,列表推导式更加优雅。
但根据个人经验(以及见到其他人犯同样的错误),我已经看到这种情况发生了足够多次,以至于我认为当这些漏洞潜入你的代码时,你所需付出的代价是不值得的。
结论:
使用 map 和 filter。它们可以防止微妙且难以诊断的作用域相关错误。
附注:
别忘了考虑在适合你情况下使用 imap 和 ifilter(在 itertools 中)!
- user541686
16
8谢谢指出这一点。我之前没有明确意识到列表推导式与其他变量在同一作用域中可能会造成问题。但是,我认为一些其他答案已经很清楚地表明,大多数情况下应该将列表推导式作为默认方法,但这也是需要记住的事情。此外,这也提醒我们要保持函数(因此作用域)简洁,并进行彻底的单元测试和使用断言语句。 - TimothyAWiseman
14这句话的意思是:@wim提到的只涉及Python 2,尽管它也适用于Python 3如果您希望向后兼容。我知道这个问题,并且我已经使用Python有一段时间了(不仅仅是几个月),但这个问题仍然发生在我身上。我见过比我更聪明和/或经验更丰富的人也犯同样的错误。如果你够聪明和/或有经验,这对你来说不是问题,那么我为你感到高兴,但我认为大多数人都不像你那样。如果大家都像你一样,那就不会有在Python 3中修复它的强烈愿望了。 - user541686
19抱歉,你在2012年末写的这篇文章,那时Python 3已经出现了,你的回答看起来像是因为复制和粘贴代码时被错误困扰而推荐了一种不受欢迎的Python编码风格。我并没有自认聪明或有经验,但我不同意你的理由可以证明这种大胆的说法。 - wim
8@wim:啥?Python 2仍然被很多地方使用,Python 3的存在并不改变这一事实。当你说“对于那些使用了几个月Python的人来说,这不是一个微妙的bug”时,其字面意思是“这只涉及到经验不足的开发者”(显然不包括你)。此外,你显然没有仔细阅读回答,因为我在粗体 中说了我正在移动而不是复制代码。复制粘贴错误在各种语言中都有,但这种类型的错误更适用于Python,因为它的作用域限制更加微妙易忘,容易忽略。 - user541686
3转换到
map和/或filter仍然不是一个逻辑上的理由。如果有的话,最直接和逻辑的翻译来避免你的问题不是map(lambda x: x ** 2, numbers)而是生成器表达式 list(x ** 2 for x in numbers),正如JeromeJ已经指出的那样,它不会泄漏。Mehrdad,请不要太在意被踩,我只是非常不同意你的推理。 - wim显示剩余11条评论
51
实际上,map和列表推导在Python 3语言中的行为非常不同。看一下以下Python 3程序:
def square(x):
return x*x
squares = map(square, [1, 2, 3])
print(list(squares))
print(list(squares))
squares时,它似乎是一个由三个元素组成的序列,但第二次却为空。在Python 2语言中,
map返回一个普通的列表,就像两种语言中的列表推导式一样。关键在于,在Python 3中map的返回值(在Python 2中为imap)不是列表,而是迭代器!当你遍历迭代器时,元素被消耗掉,这与遍历列表时不同。这就是为什么在最后一个
print(list(squares))行中,squares看起来是空的原因。总结一下:
- 处理迭代器时必须记住它们是有状态的,并且随着遍历而改变。
- 列表更可预测,因为它们只在显式修改它们时才会改变;它们是容器。
- 并且一个额外的奖励:数字、字符串和元组更可预测,因为它们根本不会改变;它们是值。
- raek
4
1这可能是列表推导式最好的论据。Python的map不是函数式map,而是一个残缺不全的函数式实现的弱化版。非常遗憾,因为我真的不喜欢推导式。 - semiomant
@semiomant 我认为懒映射(如Python3中的)比急切映射(如Python2中的)更“函数式”。例如,Haskell中的map是惰性的(好吧,Haskell中的所有东西都是惰性的...)。无论如何,懒映射更适合链接映射 - 如果您将映射应用于映射应用于映射,则在Python2中,每个中间映射调用都有一个列表,而在Python3中,您只有一个结果列表,因此它更节省内存。 - MnZrK
我想我想要的是
map生成一个数据结构,而不是迭代器。但是也许懒惰的迭代器比懒惰的数据结构更容易。值得思考。谢谢@MnZrK - semiomant你想说的是 map 返回一个可迭代对象,而不是迭代器。 - user541686
22
这里是一个可能的情况:
map(lambda op1,op2: op1*op2, list1, list2)
对比:
[op1*op2 for op1,op2 in zip(list1,list2)]
我猜测使用zip()是一个不幸而且不必要的开销,如果你坚持使用列表推导式而不是map()。希望有人能明确肯定或否定这一点。
- Andz
10
2你的第二个代码引用中应该是“for”而不是“from”,@andz,在@weakish的评论中也是如此。我本以为发现了一种新的列表推导式语法方法...可惜。 - physicsmichael
4补充一个非常晚的评论,你可以通过使用
itertools.izip使zip变得惰性化。 - tacaswell@tcaswell 没错,但人们必须知道。如果他们正在使用Python 3000,我已经为他们节省了时间:不需要寻找信息或使用
itertools.izip,因为这甚至对他们来说都不是必需的,那将是愚蠢的。*尽管这也取决于我们。在我看来,Python3 至少已经准备好了(所以我们可以推动人们使用它),但我知道这不是唯一的“问题”... - jeromej9我认为我仍然更喜欢使用
map(operator.mul, list1, list2)。在这些非常简单的左侧表达式中,列表推导变得笨拙。 - Yann Vernier1我之前没有意识到 map 函数可以接受多个可迭代对象作为输入,并因此避免使用 zip 函数。 - bli
显示剩余5条评论
21
如果您计划编写任何异步、并行或分布式代码,您可能会更喜欢使用 map 而不是列表推导式——因为大多数异步、并行或分布式程序包都提供了一个 map 函数来重载 Python 的 map。然后,通过将适当的 map 函数传递给剩下的代码,您可能不必修改原始串行代码就可以使其在并行环境中运行(等等)。
- Mike McKerns
3
1这个怎么样 https://github.com/uqfoundation/pathos/blob/master/tests/test_map.py 和这个呢 https://github.com/uqfoundation/pathos/blob/master/tests/test_star.py? - Mike McKerns
1Python的multiprocessing模块可以实现以下功能:
https://docs.python.org/2/library/multiprocessing.html - Robert L.
1感谢您是唯一一个提到并行代码中地图的重大优势的人。 - undefined
18
我发现列表推导式通常比map更能表达我的意图 - 它们都可以完成任务,但前者可以节省尝试理解可能复杂的lambda表达式所带来的心理负担。
还有一篇采访(我找不到它了)中,Guido列出了lambda和函数式函数作为他最后悔接受Python的事情,因此你可以认为它们是不符合Python风格的。
- Dan
5
10是的,叹气,但 Guido 最初在 Python 3 中想要彻底删除 lambda,但遭到了一系列反对游说,因此他放弃了,尽管我坚定地支持 - 啊,好吧,我猜 lambda 在许多简单情况下确实太方便了,唯一的问题是当它超出了简单范围或被赋给一个名称时(后一种情况下它是 def 的愚蠢副本!)。 - Alex Martelli
4你考虑的采访是这个链接:http://www.amk.ca/python/writing/gvr-interview,Guido在其中说:“有时候我会过于迅速地接受贡献,后来意识到那是一个错误。其中一例就是一些函数式编程特性,例如lambda函数。lambda是一个关键字,可以让你创建一个小型匿名函数;内置函数如map、filter和reduce会在序列类型(如列表)上运行一个函数。” - J. Taylor
4@Alex,我没有你那么多年的经验,但我见过比lambda更复杂的列表推导式。当然,滥用语言特性总是难以抵制的诱惑。有趣的是,(根据经验)列表推导式似乎比lambda更容易被滥用,尽管我不确定为什么会这样。我还要指出,“hobbled”并不总是一件坏事。缩小“这行代码可能在做的事情”的范围有时可以让读者更容易理解。例如,在C++中使用
const关键字就是这方面的一个重大突破。 - Stuart Bergguido. 这是另一个证据,表明Guido已经失去了理智。当然,“lambda”已经变得如此无用(没有语句...)以至于它们难以使用且受限制。 - WestCoastProjects
amk.ca 的链接无法打开,但我在 https://www.linuxjournal.com/article/2959 找到了同样的采访。 - jwhitlock
16
自Python 3开始,map()是一个迭代器,你需要记住你需要什么:一个迭代器还是list对象。
如@AlexMartelli已经 提到的那样,只有当你不使用lambda函数时,map()比列表推导式更快。
我将向你展示一些时间比较。
Python 3.5.2和CPython
我使用了Jupiter笔记本,特别是内置的%timeit魔术命令
测量结果:s == 1000 ms == 1000 * 1000 µs = 1000 * 1000 * 1000 ns
设置:
x_list = [(i, i+1, i+2, i*2, i-9) for i in range(1000)]
i_list = list(range(1000))
内置函数:
%timeit map(sum, x_list) # creating iterator object
# Output: The slowest run took 9.91 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 277 ns per loop
%timeit list(map(sum, x_list)) # creating list with map
# Output: 1000 loops, best of 3: 214 µs per loop
%timeit [sum(x) for x in x_list] # creating list with list comprehension
# Output: 1000 loops, best of 3: 290 µs per loop
lambda函数:
%timeit map(lambda i: i+1, i_list)
# Output: The slowest run took 8.64 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 325 ns per loop
%timeit list(map(lambda i: i+1, i_list))
# Output: 1000 loops, best of 3: 183 µs per loop
%timeit [i+1 for i in i_list]
# Output: 10000 loops, best of 3: 84.2 µs per loop
还有一种生成器表达式,详情请见PEP-0289。所以我认为将其添加到比较中会很有用
%timeit (sum(i) for i in x_list)
# Output: The slowest run took 6.66 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 495 ns per loop
%timeit list((sum(x) for x in x_list))
# Output: 1000 loops, best of 3: 319 µs per loop
%timeit (i+1 for i in i_list)
# Output: The slowest run took 6.83 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 1000000 loops, best of 3: 506 ns per loop
%timeit list((i+1 for i in i_list))
# Output: 10000 loops, best of 3: 125 µs per loop
您需要list对象:
如果是自定义函数,请使用列表推导式;如果有内置函数,请使用list(map())
您不需要list对象,只需要可迭代的对象:
始终使用map()!
- vishes_shell
2
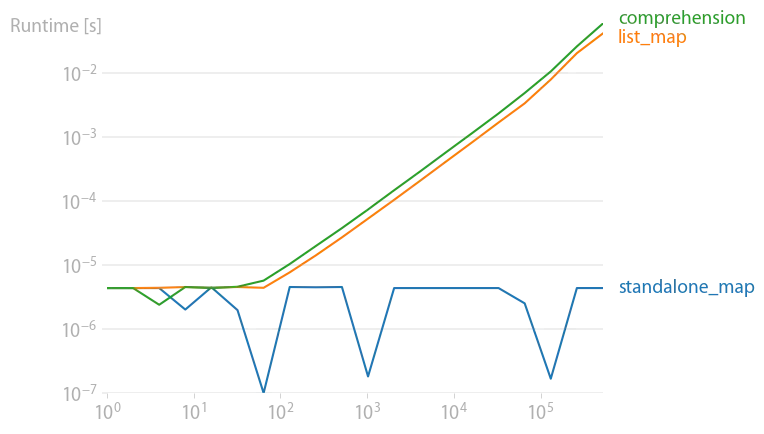
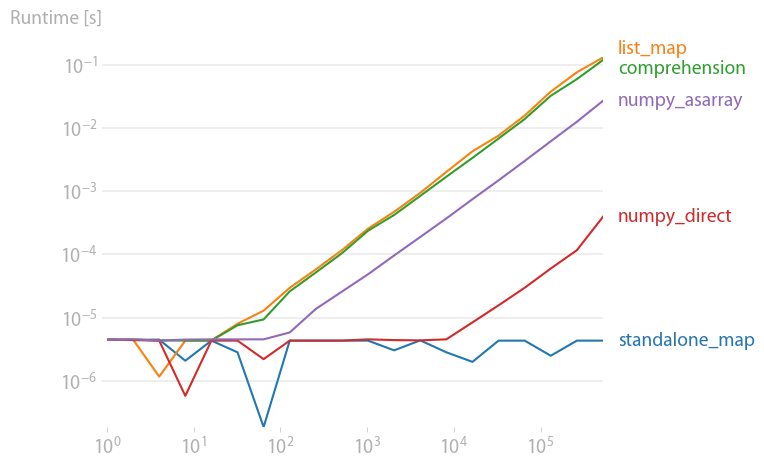
我使用了perfplot来计时一些结果(这是我的一个项目)。
正如其他人所指出的那样,map只返回一个迭代器,因此它是一个常数时间操作。当通过list()来实现迭代器时,它与列表解析相当。根据表达式,其中一个可能略微占优势,但几乎没有太大的差异。
请注意,像x ** 2等算术运算在NumPy中要快得多,特别是如果输入数据已经是NumPy数组。
hex:
x ** 2:
复制生成图表的代码:
import perfplot
def standalone_map(data):
return map(hex, data)
def list_map(data):
return list(map(hex, data))
def comprehension(data):
return [hex(x) for x in data]
b = perfplot.bench(
setup=lambda n: list(range(n)),
kernels=[standalone_map, list_map, comprehension],
n_range=[2 ** k for k in range(20)],
equality_check=None,
)
b.save("out.png")
b.show()
import perfplot
import numpy as np
def standalone_map(data):
return map(lambda x: x ** 2, data[0])
def list_map(data):
return list(map(lambda x: x ** 2, data[0]))
def comprehension(data):
return [x ** 2 for x in data[0]]
def numpy_asarray(data):
return np.asarray(data[0]) ** 2
def numpy_direct(data):
return data[1] ** 2
b = perfplot.bench(
setup=lambda n: (list(range(n)), np.arange(n)),
kernels=[standalone_map, list_map, comprehension, numpy_direct, numpy_asarray],
n_range=[2 ** k for k in range(20)],
equality_check=None,
)
b.save("out2.png")
b.show()
- Nico Schlömer
3
这里缺少了很多上下文信息:运行该程序的硬件是什么(CPU、微架构类型、核心数、L1缓存大小、L2缓存大小、L3缓存大小、时钟频率、总物理内存等)?操作系统(包括版本、补丁级别/构建号)。Python版本,Python解释器版本,Python库的版本,Python解释器的编译/优化选项等。在什么条件下运行的? - Peter Mortensen
1@PeterMortensen,我认为您提到的那些并不重要,因为所有测试都在同一台计算机上运行。 - Scott
standalone_map 代码仅仅是实例化了一个 map 对象,并没有执行任何迭代 - 也就是说,六边形/正方形值的计算实际上从未发生。这当然解释了性能结果。在图表中包含这个并不太有用。 - Karl Knechtel2
我进行了一个快速测试,比较了三种调用对象方法的方法。在这种情况下,时间差异微不足道,这取决于所涉及的函数(请参见@Alex Martelli的 回答)。这里,我研究了以下方法:
1. 直接调用对象方法
2. 使用call()方法调用对象方法
3. 使用apply()方法调用对象方法
# map_lambda
list(map(lambda x: x.add(), vals))
# map_operator
from operator import methodcaller
list(map(methodcaller("add"), vals))
# map_comprehension
[x.add() for x in vals]
我观察了整数(Python中的int)和浮点数(Python中的float)列表(存储在变量vals中)的递增列表大小。考虑下面的虚拟类DummyNum:
class DummyNum(object):
"""Dummy class"""
__slots__ = 'n',
def __init__(self, n):
self.n = n
def add(self):
self.n += 5
具体来说,需要翻译的是
add方法。在Python中,__slots__属性是一种简单的优化方式,用于定义类(属性)所需的总内存,从而减小内存大小。下面是结果图表:
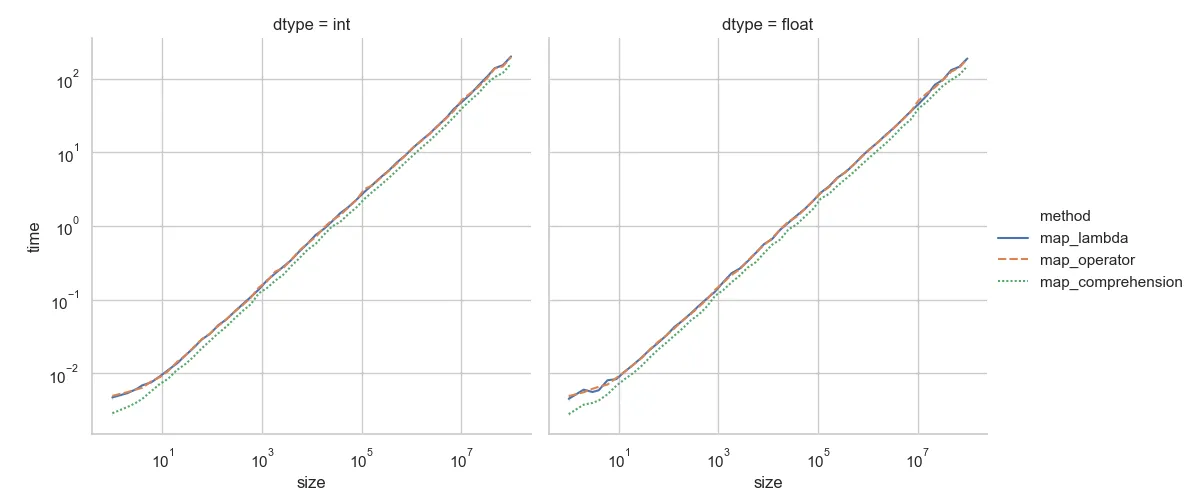 正如之前所述,所采用的技术差异微乎其微,您应该以最易读或适合特定情况的方式编码。在这种情况下,列表推导式(
正如之前所述,所采用的技术差异微乎其微,您应该以最易读或适合特定情况的方式编码。在这种情况下,列表推导式(map_comprehension技术)对于对象中的两种添加类型都是最快的,尤其是对于较短的列表。请访问此pastebin获取用于生成图表和数据的源代码。
- craymichael
3
2如其他答案中已经解释的那样,只有在以完全相同的方式调用函数时(即
[*map(f, vals)]与[f(x) for x in vals])才能使map更快。因此,list(map(methodcaller("add"), vals))比[methodcaller("add")(x) for x in vals]更快。当循环对应项使用不同的调用方法以避免一些开销时(例如,x.add()避免了methodcaller或lambda表达式的开销),map可能不会更快。对于这个特定的测试用例,[*map(DummyNum.add, vals)]将更快(因为DummyNum.add(x)和x.add()基本上具有相同的性能)。 - GZ01顺便提一下,显式调用
list() 比列表推导式稍微慢一些。为了公平比较,您需要编写 [*map(...)]。 - GZ0@GZ0,非常感谢您的反馈!所有的意见都很合理,我并不知道
list() 调用会增加负担。我应该花更多时间阅读答案。我将重新运行这些测试以进行公正比较,无论差异有多么微不足道。 - craymichael网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接