在Python中,何时应使用生成器表达式,何时应使用列表推导?
# Generator expression
(x*2 for x in range(256))
# List comprehension
[x*2 for x in range(256)]
在Python中,何时应使用生成器表达式,何时应使用列表推导?
# Generator expression
(x*2 for x in range(256))
# List comprehension
[x*2 for x in range(256)]
John的答案很好(列表推导式在需要多次迭代时更好)。但是,如果您想使用任何列表方法,则应使用列表。例如,以下代码将无法工作:
def gen():
return (something for something in get_some_stuff())
print gen()[:2] # generators don't support indexing or slicing
print [5,6] + gen() # generators can't be added to lists
如果你只需要迭代一次,基本上使用生成器表达式。如果你想存储和使用生成的结果,那么列表解析可能更好。
由于性能是选择其中一个的最常见原因,我的建议是不要担心它,只需选择其中一个;如果你发现程序运行太慢,那么只有在这种情况下才应该回去担心调优代码。
a = [1, 2, 3] b = [4, 5, 6] a.extend(b) -- 现在a将变成[1, 2, 3, 4, 5, 6]。(你可以在注释中添加换行符吗?) - jarvistevea = (x for x in range(0,10)),b = [1,2,3]。a.extend(b) 会引发异常。而 b.extend(a) 则会计算出 a 中的所有元素,这种情况下最初将其定义为生成器是没有意义的。 - Slater Victoroff遍历生成器表达式或列表推导式将会产生相同的结果。但是,列表推导式首先会在内存中创建整个列表,而生成器表达式则会动态创建项目,因此您可以将其用于非常大的(甚至是无限的)序列。
itertools.count(n) 是一个无限的整数序列,从n开始,所以(2 ** item for item in itertools.count(n))将是一个无限的2的幂的序列,从2 ** n开始。 - Kevin当结果需要多次迭代或速度至关重要时,请使用列表推导式。在范围很大或无限的情况下,请使用生成器表达式。
有关更多信息,请参见生成器表达式和列表推导式。
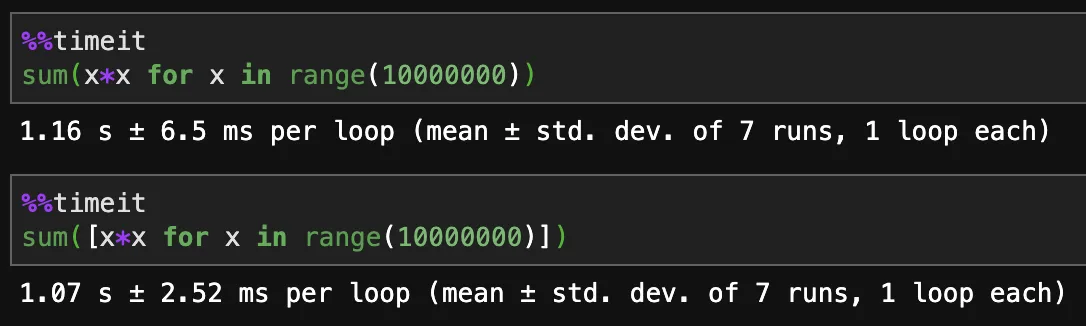
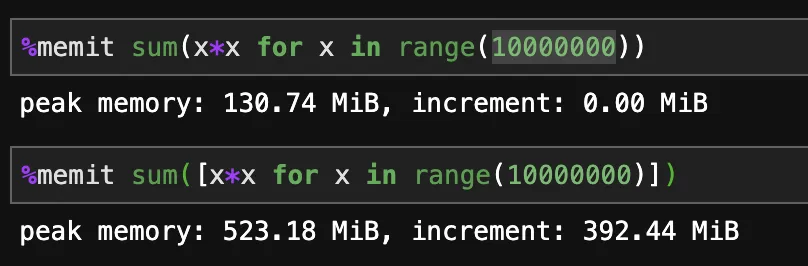
%timeit基准测试证实了这一点——即列表推导式略微比生成器更快(正如@HassanBaig所说,这不是我预期的)。但是,使用%memit进行测试后发现,列表推导式的内存消耗比生成器要高得多。 - Nate Anderson重要的一点是列表推导式创建一个新的列表。生成器创建一个可迭代对象,将在你消耗元素时即时“过滤”源数据。
假设你有一个名为“hugefile.txt”的2TB日志文件,并且想要获取所有以单词“ENTRY”开头的行的内容和长度。
因此,你开始尝试编写一个列表推导式:
logfile = open("hugefile.txt","r")
entry_lines = [(line,len(line)) for line in logfile if line.startswith("ENTRY")]
这个方法会读取整个文件,处理每一行,并将匹配的行存储在数组中。因此,该数组最多可能包含2TB的内容。这需要大量的RAM,对您的用途可能不实际。
因此,我们可以使用生成器来对我们的内容应用"过滤器"。只有在开始迭代结果时才会实际读取数据。
logfile = open("hugefile.txt","r")
entry_lines = ((line,len(line)) for line in logfile if line.startswith("ENTRY"))
我们的文件中还没有读取任何一行内容。实际上,假设我们想进一步筛选结果:
long_entries = ((line,length) for (line,length) in entry_lines if length > 80)
虽然还没有读取任何内容,但我们现在已经指定了两个生成器,它们将按照我们的意愿对数据进行操作。
让我们将筛选后的行写入另一个文件:
outfile = open("filtered.txt","a")
for entry,length in long_entries:
outfile.write(entry)
现在我们读取输入文件。随着我们的for循环继续请求更多行,long_entries生成器从entry_lines生成器中获取行,仅返回长度大于80个字符的行。反过来,entry_lines生成器从logfile迭代器中请求经过筛选的行(如指示),而logfile迭代器则读取文件。
因此,与其以完全填充的列表形式“推送”数据到输出函数,不如为输出函数提供一种只在需要时“拉取”数据的方式。在我们的情况下,这样做更加高效,但不够灵活。生成器是一种单向、一次性的方式;我们读取的日志文件数据会立即被丢弃,因此我们无法返回到先前的行。另一方面,我们也不必担心在完成后保留数据。
生成器表达式的好处在于它使用的内存更少,因为它不会一次性构建整个列表。生成器表达式最好用于列表是中间结果的情况,例如对结果求和或将结果创建为字典。
例如:
sum(x*2 for x in xrange(256))
dict( (k, some_func(k)) for k in some_list_of_keys )
reversed( [x*2 for x in xrange(256)] )
sum(x*2 for x in xrange(256)) - u0b34a0f6aesorted和reversed可以在任何可迭代对象上运行,包括生成器表达式。 - marr75当从可变对象(如列表)创建生成器时,请注意生成器将在使用生成器时的列表状态上进行评估,而不是在生成器创建时的状态上进行评估:
>>> mylist = ["a", "b", "c"]
>>> gen = (elem + "1" for elem in mylist)
>>> mylist.clear()
>>> for x in gen: print (x)
# nothing
如果您的列表有可能被修改(或列表内部的可变对象),但您需要在生成器创建时保留状态,则需要改用列表推导式。
gen进行迭代的过程中修改底层列表将导致不可预测的结果,就像直接迭代列表一样。 - Karl KnechtelPython 3.7:
列表推导式更快。
生成器的内存效率更高。
正如其他人所说,如果你要处理无限量的数据,最终你需要使用生成器。对于相对静态的小型和中型任务,需要速度的情况下,最好使用列表推导式。
any 并且预计有早期出现的 False 元素,那么生成器比列表推导式能更大幅度地提升性能。但是如果两种方法都会被用尽,那么列表推导式通常更快。你真的需要对应用程序进行分析并检查。 - ggorlen我正在使用Hadoop Mincemeat模块。我认为这是一个值得注意的很好的例子:
import mincemeat
def mapfn(k,v):
for w in v:
yield 'sum',w
#yield 'count',1
def reducefn(k,v):
r1=sum(v)
r2=len(v)
print r2
m=r1/r2
std=0
for i in range(r2):
std+=pow(abs(v[i]-m),2)
res=pow((std/r2),0.5)
return r1,r2,res
这里的生成器从一个文本文件中获取数字(最大可达15GB),并使用Hadoop的map-reduce对这些数字进行简单的数学运算。如果我没有使用yield函数,而是使用列表推导式,那么计算总和和平均值所需的时间会更长(更不用说空间复杂度了)。
Hadoop是使用生成器的一个很好的例子,可以充分利用所有优势。
一些关于Python内置函数的笔记:
如果需要利用any或all的短路行为,请使用生成器表达式。这些函数被设计为在知道答案时停止迭代,但列表推导必须在调用函数之前评估每个元素。
例如,如果我们有
from time import sleep
def long_calculation(value):
sleep(1) # for simulation purposes
return value == 1
然后 any([long_calculation(x) for x in range(10)]) 大约需要十秒钟,因为对于每个 x 都会调用 long_calculation。而 any(long_calculation(x) for x in range(10)) 只需要大约两秒钟,因为 long_calculation 仅会使用 0 和 1 这两个输入。
当 any 和 all 遍历列表推导式时,它们一旦知道答案(即 any 找到真结果或 all 找到假结果),就会停止检查元素的 真值;但是,与推导式实际完成的工作相比,这通常微不足道。
当可以使用生成器表达式时,它们当然更节省内存。当使用非短路的 min、max 和 sum 时,列表推导式将稍微更快(此处显示了 max 的时间):
$ python -m timeit "max(_ for _ in range(1))"
500000 loops, best of 5: 476 nsec per loop
$ python -m timeit "max([_ for _ in range(1)])"
500000 loops, best of 5: 425 nsec per loop
$ python -m timeit "max(_ for _ in range(100))"
50000 loops, best of 5: 4.42 usec per loop
$ python -m timeit "max([_ for _ in range(100)])"
100000 loops, best of 5: 3.79 usec per loop
$ python -m timeit "max(_ for _ in range(10000))"
500 loops, best of 5: 468 usec per loop
$ python -m timeit "max([_ for _ in range(10000)])"
500 loops, best of 5: 442 usec per loop
[exp for x in iter]只是list((exp for x in iter))的语法糖吗?还是有执行上的差别? - b0fhX = [x**2 for x in range(5)]; print x和Y = list(y**2 for y in range(5)); print y,后者会报错。但在Python3中,列表解析确实是你所期望的被馈送到list()函数中的生成器表达式的语法糖,因此循环变量将不会再泄漏出来。详见PEP 0289。 - Bas Swinckels