我正在努力使以下查询在合理的性能下执行:
UPDATE order_item_imprint SET item_new_id = oi.item_new_id
FROM order_item oi
INNER JOIN order_item_imprint oii ON oi.item_number = oii.item_id
目前,它在8天内无法完成,所以我们将其终止。查询解释如下:
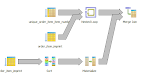
Merge Join (cost=59038021.60..33137238641.84 rows=1432184234121 width=1392)
Merge Cond: ((oi.item_number)::text = (oii.item_id)::text)
-> Nested Loop (cost=0.00..10995925524.15 rows=309949417305 width=1398)
-> Index Scan using unique_order_item_item_number on order_item oi (cost=0.00..608773.05 rows=258995 width=14)
-> Seq Scan on order_item_imprint (cost=0.00..30486.39 rows=1196739 width=1384)
-> Materialize (cost=184026.24..198985.48 rows=1196739 width=6)
-> Sort (cost=184026.24..187018.09 rows=1196739 width=6)
Sort Key: oii.item_id
-> Seq Scan on order_item_imprint oii (cost=0.00..30486.39 rows=1196739 width=6)
我在两个表上建立了索引,并确保比较字段具有相同的类型和大小。我现在试图更改postgresql服务器配置,以希望有所帮助,但我不确定它是否有效。
order_item_imprint表的大小约为110万,并且磁盘占用空间为145MB,而order_item表的大小约为其三分之一。
主要目标是我需要能够在几小时的维护窗口期间运行此查询以及其他几个查询。
在执行计划之前已运行自动清理和分析。