我在一个大表(例如8GB)上运行了一个更新操作,只是简单地更新了表中的3个字段。在postgresql 9.1下运行没有问题,虽然需要40-60分钟,但它可以正常工作。我在9.4数据库中运行相同的查询(全新创建,未升级),开始更新操作时速度也很快,但后来变慢了。它只使用了约2%的CPU,IO的水平为4-5MB/s,就这样卡在那里。没有锁定、没有其他查询或连接,只有这个单独的更新SQL在服务器上。
以下是SQL语句。"lookup"表有12条记录。查找只能返回一行,它将离散的范围(SMALLINT,-32768..+32767)分成不重叠的区域。"src"和"dest"表约有6000万条记录。
我觉得我的硬盘变慢了,但我可以同时复制1GB的文件和查询执行,并且它以大于40MB/s的速度运行,而我只有一个磁盘(它是带有ISCSI媒体的虚拟机)。所有其他磁盘操作都不受影响,还有大量IO带宽。与此同时,PostgreSQL只是坐在那里,几乎没有做任何事情,非常缓慢地运行。
我有两个虚拟化的Linux服务器,一个运行PostgreSQL 9.1,另一个运行9.4。这两台服务器的PostgreSQL配置几乎相同。
有其他人有类似的经历吗?我想不出更多的办法了。救命啊。
编辑:查询“运行”了20小时,我不得不杀掉连接并重新启动服务器。令人惊讶的是,它并没有通过查询杀死连接。
“邮政管理员命令此服务器进程回滚当前事务并退出,因为另一个服务器进程异常退出并可能损坏了共享内存” - 这是否表明PostgreSQL中存在漏洞?
编辑: 我测试了9.1、9.3和9.4。9.1和9.3都没有经历过减速。9.4在大型事务上始终会出现减速。我注意到当事务开始时,htop监视器显示高CPU使用率和进程状态为“R”(运行)。然后它逐渐变成低CPU使用率和状态“D”-磁盘(见截图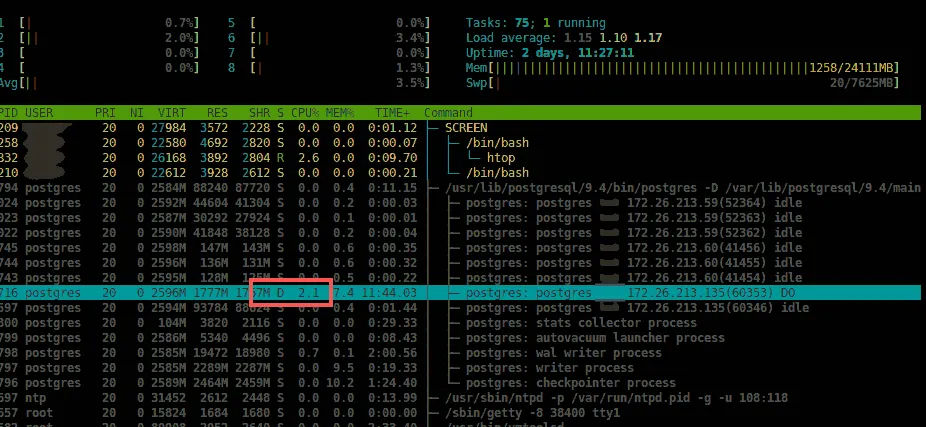 )。我最大的问题是为什么9.4与9.1和9.3不同?我有十几台服务器,这种效果在整个计算机系统中都会观察到。
)。我最大的问题是为什么9.4与9.1和9.3不同?我有十几台服务器,这种效果在整个计算机系统中都会观察到。
以下是SQL语句。"lookup"表有12条记录。查找只能返回一行,它将离散的范围(SMALLINT,-32768..+32767)分成不重叠的区域。"src"和"dest"表约有6000万条记录。
UPDATE dest SET
field1 = src.field1,
field2 = src.field2,
field3_id = (SELECT lookup.id FROM lookup WHERE src.value BETWEEN lookup.min AND lookup.max)
FROM src
WHERE dest.id = src.id;
我觉得我的硬盘变慢了,但我可以同时复制1GB的文件和查询执行,并且它以大于40MB/s的速度运行,而我只有一个磁盘(它是带有ISCSI媒体的虚拟机)。所有其他磁盘操作都不受影响,还有大量IO带宽。与此同时,PostgreSQL只是坐在那里,几乎没有做任何事情,非常缓慢地运行。
我有两个虚拟化的Linux服务器,一个运行PostgreSQL 9.1,另一个运行9.4。这两台服务器的PostgreSQL配置几乎相同。
有其他人有类似的经历吗?我想不出更多的办法了。救命啊。
编辑:查询“运行”了20小时,我不得不杀掉连接并重新启动服务器。令人惊讶的是,它并没有通过查询杀死连接。
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE pid <> pg_backend_pid() AND datname = current_database();
服务器生成了以下日志:
2015-05-21 12:41:53.412 EDT FATAL: terminating connection due to administrator command
2015-05-21 12:41:53.438 EDT FATAL: terminating connection due to administrator command
2015-05-21 12:41:53.438 EDT STATEMENT: UPDATE <... this is 60,000,000 record table update statement>
此外,服务器重启时间很长,生成了以下日志:
2015-05-21 12:43:36.730 EDT LOG: received fast shutdown request
2015-05-21 12:43:36.730 EDT LOG: aborting any active transactions
2015-05-21 12:43:36.730 EDT FATAL: terminating connection due to administrator command
2015-05-21 12:43:36.734 EDT FATAL: terminating connection due to administrator command
2015-05-21 12:43:36.747 EDT LOG: autovacuum launcher shutting down
2015-05-21 12:44:36.801 EDT LOG: received immediate shutdown request
2015-05-21 12:44:36.815 EDT WARNING: terminating connection because of crash of another server process
2015-05-21 12:44:36.815 EDT DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
“邮政管理员命令此服务器进程回滚当前事务并退出,因为另一个服务器进程异常退出并可能损坏了共享内存” - 这是否表明PostgreSQL中存在漏洞?
编辑: 我测试了9.1、9.3和9.4。9.1和9.3都没有经历过减速。9.4在大型事务上始终会出现减速。我注意到当事务开始时,htop监视器显示高CPU使用率和进程状态为“R”(运行)。然后它逐渐变成低CPU使用率和状态“D”-磁盘(见截图
)。我最大的问题是为什么9.4与9.1和9.3不同?我有十几台服务器,这种效果在整个计算机系统中都会观察到。
vacuum analyze吗? - joop