Pandas提供了一个
它还提供了关于
以下是
describe()函数,用于计算DataFrame的一些汇总统计信息。该函数的输出结果是另一个DataFrame,因此只需调用to_html()即可轻松导出HTML。它还提供了关于
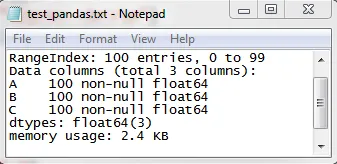
DataFrame的信息,使用info()函数进行查询,但是该函数会打印输出结果,返回None。有没有办法获得与DataFrame相同的信息或以其他方式导出到HTML呢?以下是
info()函数的示例参考:<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 7 columns):
0 5 non-null float64
1 5 non-null float64
2 5 non-null float64
3 5 non-null float64
4 5 non-null float64
5 5 non-null float64
6 5 non-null float64
dtypes: float64(7)
memory usage: 360.0 bytes