你可以通过查看查询计划来了解索引的更新情况。考虑这个只有非聚集索引的堆表。
CREATE TABLE dbo.BulkInsertTest(
Column1 int NOT NULL
, Column2 int NOT NULL
, Column3 int NOT NULL
, Column4 int NOT NULL
, Column5 int NOT NULL
);
CREATE INDEX BulkInsertTest_Column1 ON dbo.BulkInsertTest(Column1);
CREATE INDEX BulkInsertTest_Column2 ON dbo.BulkInsertTest(Column2);
CREATE INDEX BulkInsertTest_Column3 ON dbo.BulkInsertTest(Column3);
CREATE INDEX BulkInsertTest_Column4 ON dbo.BulkInsertTest(Column4);
CREATE INDEX BulkInsertTest_Column5 ON dbo.BulkInsertTest(Column5);
GO
以下是单例
INSERT的执行计划。
INSERT INTO dbo.BulkInsertTest(Column1, Column2, Column3, Column4, Column5) VALUES
(1, 2, 3, 4, 5);

执行计划仅显示表插入运算符,因此新的非聚集索引行是在表插入操作本身中内在插入的。大量单例INSERT语句将为每个插入语句产生相同的计划。
通过使用行构造函数指定大量行的单个INSERT语句可以获得类似的计划,唯一的区别是添加了常量扫描运算符以发出行。
INSERT INTO dbo.BulkInsertTest(Column1, Column2, Column3, Column4, Column5) VALUES
(1, 2, 3, 4, 5)
,(1, 2, 3, 4, 5)
,(1, 2, 3, 4, 5)
,...
,(1, 2, 3, 4, 5);

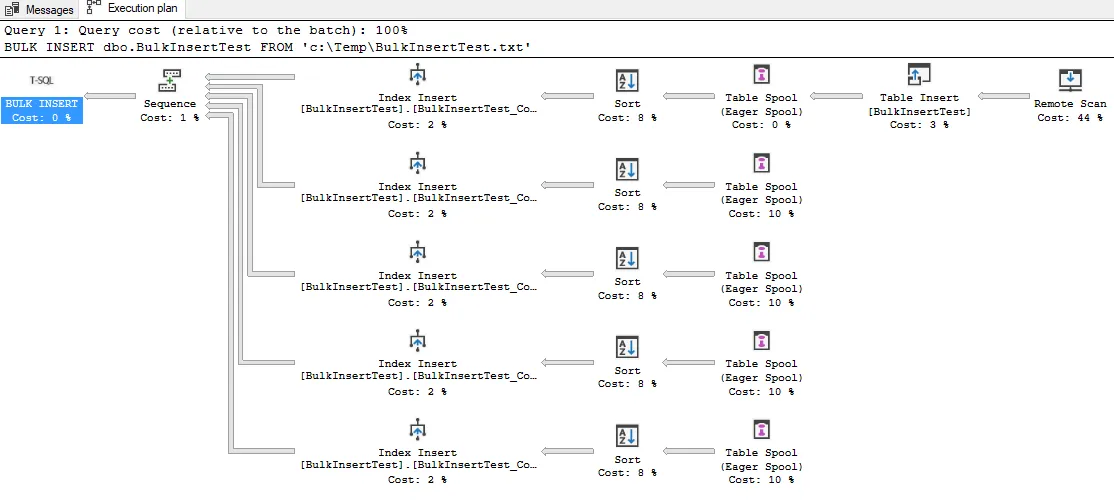
这是一个 T-SQL
BULK INSERT 语句的执行计划(使用一个空文件作为源)。使用
BULK INSERT,SQL Server 添加了额外的查询计划操作符以优化索引插入。行被插入表后被暂存,然后从暂存区中的行进行排序并分别作为大规模插入操作插入到每个索引中。这种方法减少了大量插入操作的开销。您也可以看到类似的
INSERT...SELECT 查询计划。
BULK INSERT dbo.BulkInsertTest
FROM 'c:\Temp\BulkInsertTest.txt';
我验证了SqlBulkCopy生成与T-SQL BULK INSERT相同的执行计划,通过使用Extended Event跟踪捕获实际计划。以下是我使用的跟踪DDL和PowerShell脚本。
跟踪DDL:
CREATE EVENT SESSION [SqlBulkCopyTest] ON SERVER
ADD EVENT sqlserver.query_post_execution_showplan(
ACTION(sqlserver.client_app_name,sqlserver.sql_text)
WHERE ([sqlserver].[equal_i_sql_unicode_string]([sqlserver].[client_app_name],N'SqlBulkCopyTest')
AND [sqlserver].[like_i_sql_unicode_string]([sqlserver].[sql_text],N'insert bulk%')
))
ADD TARGET package0.event_file(SET filename=N'SqlBulkCopyTest');
GO
PowerShell脚本:
$connectionString = "Data Source=.;Initial Catalog=YourUserDatabase;Integrated Security=SSPI;Application Name=SqlBulkCopyTest"
$dt = New-Object System.Data.DataTable;
$null = $dt.Columns.Add("Column1", [System.Type]::GetType("System.Int32"))
$null = $dt.Columns.Add("Column2", [System.Type]::GetType("System.Int32"))
$null = $dt.Columns.Add("Column3", [System.Type]::GetType("System.Int32"))
$null = $dt.Columns.Add("Column4", [System.Type]::GetType("System.Int32"))
$null = $dt.Columns.Add("Column5", [System.Type]::GetType("System.Int32"))
$row = $dt.NewRow()
[void]$dt.Rows.Add($row)
$row["Column1"] = 1
$row["Column2"] = 2
$row["Column3"] = 3
$row["Column4"] = 4
$row["Column5"] = 5
$bcp = New-Object System.Data.SqlClient.SqlBulkCopy($connectionString)
$bcp.DestinationTableName = "dbo.BulkInsertTest"
$bcp.WriteToServer($dt)
编辑
感谢 Vladimir Baranov 提供的Microsoft 数据平台 MVP Paul White 的博客文章,详细介绍了 SQL Server 的基于成本的索引维护策略。
编辑2
从您修改后的问题中我看到,您实际上的情况是一个有聚集索引的表而不是堆。计划将类似于上面的堆示例,除了数据将使用聚集索引插入运算符而不是表插入运算符进行插入。
在向具有聚集索引的表进行批量插入操作期间可以指定 ORDER 提示。当指定顺序与聚集索引的顺序匹配时,SQL Server 可以在聚集索引插入之前消除排序运算符,因为它假定数据已按提示排序。
很遗憾,System.Data.SqlClient.SqlBulkCopy不支持通过该API进行ORDER提示。正如@benjol在评论中提到的那样,较新的Microsoft.Data.SqlClient.SqlBulkCopy包括一个ColumnOrderHints属性,可以指定目标表聚集索引列和排序顺序。
sys.fn_dblog函数)将使您能够精确了解SQL Server在每个插入、批量或其他操作中正在执行的操作。例如。 - Jeroen Mostert