我将您的原始代码与我的代码进行了快速比较,以下是时间差异:
您的代码
%%timeit
'''
ID State perform A B C D
234 AK 75.8456 1 0 0 0
284 MN 78.6752 0 0 1 0
'''
dfr = pd.read_clipboard()
df_a = dfr[['ID', 'State', 'perform', 'A']].groupby(['ID', 'State']).corr().ix[1::2][['A']].reset_index(2).drop('level_2', axis=1)
df_b = dfr[['ID', 'State', 'perform', 'B']].groupby(['ID', 'State']).corr().ix[1::2][['B']].reset_index(2).drop('level_2', axis=1)
df_c = dfr[['ID', 'State', 'perform', 'C']].groupby(['ID', 'State']).corr().ix[1::2][['C']].reset_index(2).drop('level_2', axis=1)
df_d = dfr[['ID', 'State', 'perform', 'D']].groupby(['ID', 'State']).corr().ix[1::2][['D']].reset_index(2).drop('level_2', axis=1)
df = df_a.merge(df_b, left_index=True, right_index=True)
df = df.merge(df_c, left_index=True, right_index=True)
df = df.merge(df_d, left_index=True, right_index=True)
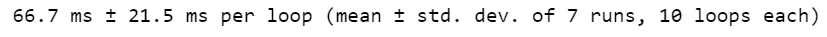
“我的代码”
%%timeit
# data
'''
ID State perform A B C D
234 AK 75.8456 1 0 0 0
284 MN 78.6752 0 0 1 0
'''
# make dataframe
df = pd.read_clipboard()
# make other dfs
df_a = df.loc[:, :'A'].groupby([
'ID',
'State'
]).corr().iloc[1::2][['A']].reset_index(2, drop = True)
df_b = df.loc[:, [
'ID',
'State',
'perform',
'B'
]].groupby([
'ID',
'State'
]).corr().iloc[1::2][['B']].reset_index(2, drop = True)
df_c = df.loc[:, [
'ID',
'State',
'perform',
'C'
]].groupby([
'ID',
'State'
]).corr().iloc[1::2][['C']].reset_index(2, drop = True)
df_d = df.loc[:, [
'ID',
'State',
'perform',
'D'
]].groupby([
'ID',
'State'
]).corr().iloc[1::2][['D']].reset_index(2, drop = True)
# concat them together
pd.concat([df_a, df_b, df_c, df_d], axis = 1)
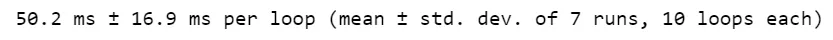
虽然差异可能仍然可以忽略不计。
编辑
决定尝试使用 for 循环来消除重复的代码。运行时间有所改善:
%%timeit
'''
ID State perform A B C D
234 AK 75.8456 1 0 0 0
284 MN 78.6752 0 0 1 0
'''
df = pd.read_clipboard()
letters = ['A', 'B', 'C', 'D']
list_of_dfs = []
for letter in letters:
list_of_dfs.append(df.loc[:, [
'ID',
'State',
'perform',
letter
]].groupby([
'ID',
'State'
]).corr().iloc[1::2][[letter]].reset_index(2, drop = True))
pd.concat(list_of_dfs, axis = 1)
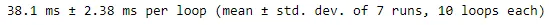
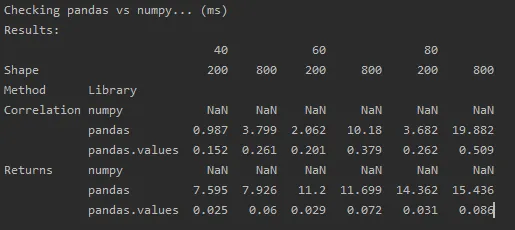
df[cols].corrwith(series)有什么问题吗? - cs95.reset_index(2).drop('level_2', axis = 1)改为.reset_index(2, drop=True)。这样就可以少一个链接的函数,但是能够完成同样的操作。 - Ian Thompson