我有一个由DataFrame组成的字典,我想用它来绘制图表。以下是数据示例:
最终,我需要9个单独的图表,显示
通常我会解释我尝试自己解决问题的方案。然而,在这种情况下,我对可能的解决方案一无所知。。
注意:实际数据集是10x10
import pandas as pd
import numpy as np
np.random.seed(5)
first = pd.DataFrame(columns=range(1,4),data=np.random.rand(3,3), index=range(1,4))
second = pd.DataFrame(columns=range(1,4),data=np.random.rand(3,3)+0.2, index=range(1,4))
third = pd.DataFrame(columns=range(1,4),data=np.random.rand(3,3)+0.05, index=range(1,4))
fourth= pd.DataFrame(columns=range(1,4),data=np.random.rand(3,3)-0.2, index=range(1,4))
d={'frame_1':first,'frame_2':second,'frame_3':third,'frame_4':fourth}
#This is what it looks like
d
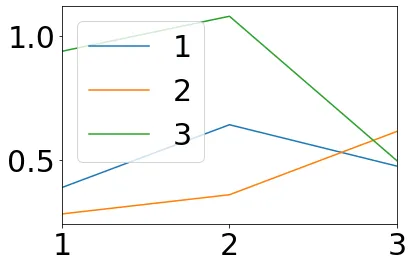
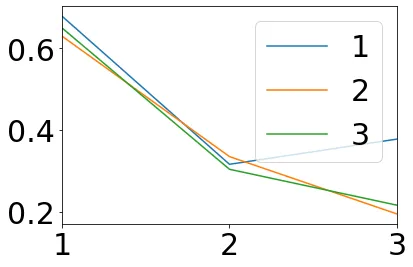
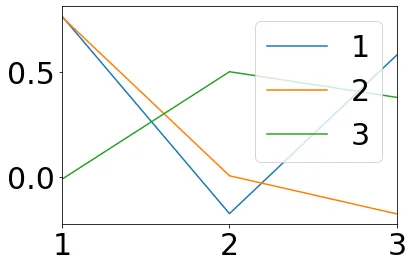
{'frame_1': 1 2 3
1 0.221993 0.870732 0.206719
2 0.918611 0.488411 0.611744
3 0.765908 0.518418 0.296801, 'frame_2': 1 2 3
1 0.387721 0.280741 0.938440
2 0.641309 0.358310 1.079937
3 0.474086 0.614235 0.496080, 'frame_3': 1 2 3
1 0.678788 0.629838 0.649929
2 0.315819 0.334686 0.303588
3 0.377564 0.194164 0.215613, 'frame_4': 1 2 3
1 0.763931 0.760227 -0.011585
2 -0.175693 0.004556 0.499844
3 0.579515 -0.177067 0.377663}
最终,我需要9个单独的图表,显示
DataFrame(11、12、13等)中每个元素组合的演变情况,x轴为1、2、3、4(与“frame_1”、“frame_2”等相关)。明确一点,这意味着第一个图表(与11有关)应该包含值0.221993、0.387721、0.678788和0.763931。通常我会解释我尝试自己解决问题的方案。然而,在这种情况下,我对可能的解决方案一无所知。。
注意:实际数据集是10x10
DataFrames,而dictionary包含75个这样的数据框,因此我希望尽可能自动化。