NODE和VERSION。VERSION通过VERSION_OF关系连接到NODE。VERSION节点确实具有两个属性from和until,表示有效时间跨度-可以都是NULL(在Neo4j术语中不存在)表示无限制。NODE可以通过HAS_CHILD关系连接。同样,这些关系也有两个属性from和until,表示有效时间跨度-可以都是NULL(在Neo4j术语中不存在)表示无限制。
编辑:版本节点和HAS_CHILD关系上的有效日期是独立的(即使示例巧合地显示它们对齐)。
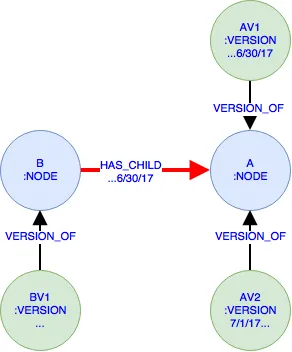
NODE: A 和 B。 A 有两个版本VERSION: AV1 直到6/30/17和从7/1/17开始的 AV2,而B只有一个无限制的版本BV1。在6/30/17之前,B通过HAS_CHILD关系连接到A。现在的挑战是查询图形以获取所有在特定时间不是child(即根节点)的节点。根据上面的例子,如果查询日期为6/1/17,则查询应该仅返回B,但如果查询日期为8/1/17,则应返回B和A(因为从7/1/17起A不再是B的child)。
当前查询与上述查询大致相似:
MATCH (n1:NODE)
OPTIONAL MATCH (n1)<-[c]-(n2:NODE), (n2)<-[:VERSION_OF]-(nv2:ITEM_VERSION)
WHERE (c.from <= {date} <= c.until)
AND (nv2.from <= {date} <= nv2.until)
WITH n1 WHERE c IS NULL
MATCH (n1)<-[:VERSION_OF]-(nv1:ITEM_VERSION)
WHERE nv1.from <= {date} <= nv1.until
RETURN n1, nv1
ORDER BY toLower(nv1.title) ASC
SKIP 0 LIMIT 15
这个查询一般情况下运行良好,但在处理大型数据集(与实际生产数据集相当)时开始变得非常缓慢。使用 20-30k 个 NODE(大约有两倍数量的 VERSION),真正的查询在运行 Mac OS X 上的小 Docker 容器上大约需要 500-700 毫秒,这是可以接受的。但是,在具有 1.5M 个 NODE(大约有两倍数量的 VERSION)的情况下,真正的查询在裸机服务器上(除了 Neo4j 之外没有其他运行内容)需要略多于 1 分钟。这是不可接受的。
我们有什么选项来调整此查询吗?是否有更好的方法来处理 NODE 的版本控制(我怀疑这不是性能问题)或关系的有效性?我知道无法对关系属性进行索引,因此可能有更好的模式用于处理这些关系的有效性。
任何帮助或哪怕最微小的提示都将不胜感激。
Michael Hunger 的回答 后编辑:
Percentage of root nodes:
With the current example data set (1.5M nodes) the result set contains about 2k rows. That's less than 1%.
ITEM_VERSIONnode in firstMATCH:We're using the
ITEM_VERSIONnv2to filter the result set toITEMnodes that have no connection otherITEMnodes at the given date. That means that either no relationship must exist that is valid for the given date or the connected item must not have anITEM_VERSIONthat is valid for the given date. I'm trying to illustrate this:// date 6/1/17 // n1 returned because relationship not valid (nv1 ...)->(n1)-[X_HAS_CHILD ...6/30/17]->(n2)<-(nv2 ...) // n1 not returned because relationship and connected item n2 valid (nv1 ...)->(n1)-[X_HAS_CHILD ...]->(n2)<-(nv2 ...) // n1 returned because connected item n2 not valid even though relationship is valid (nv1 ...)->(n1)-[X_HAS_CHILD ...]->(n2)<-(nv2 ...6/30/17)No use of relationship-types:
The problem here is that the software features a user-defined schema and
ITEMnodes are connected by custom relationship-types. As we can't have multiple types/labels on a relationship the only common characteristic for these kind of relationships is that they all start withX_. That's been left out of the simplified example here. Would searching with the predicatetype(r) STARTS WITH 'X_'help here?
HAS_CHILD关系相同。但这些可以是任意日期。 - Stefan Gehrig-[:X_FOO|:X_BAR*]->。 - Michael HungerX_关系的大约数量为13.5M,而总关系数为19.5M-因此数据库中约70%的关系是自定义的。 - Stefan Gehrig