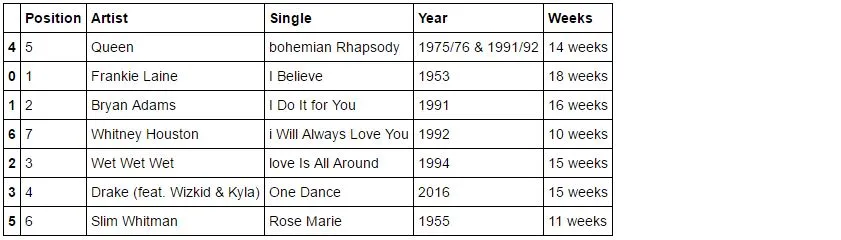
我在Python中有一个Pandas数据框。数据框的内容来自于这里。我稍微修改了“Single”列中第一个字母的大小写。以下是我的代码:
import pandas as pd
df = pd.read_csv('test.csv')
print df
Position Artist Single Year Weeks
1 Frankie Laine I Believe 1953 18 weeks
2 Bryan Adams I Do It for You 1991 16 weeks
3 Wet Wet Wet love Is All Around 1994 15 weeks
4 Drake (feat. Wizkid & Kyla) One Dance 2016 15 weeks
5 Queen bohemian Rhapsody 1975/76 & 1991/92 14 weeks
6 Slim Whitman Rose Marie 1955 11 weeks
7 Whitney Houston i Will Always Love You 1992 10 weeks
我想按照单一列进行升序排序(从a到z)。当我运行时:
df.sort_values(by='Single',inplace=True)
看起来排序无法将大小写字母组合在一起。这是我得到的结果:
Position Artist Single Year Weeks
1 Frankie Laine I Believe 1953 18 weeks
2 Bryan Adams I Do It for You 1991 16 weeks
4 Drake (feat. Wizkid & Kyla) One Dance 2016 15 weeks
6 Slim Whitman Rose Marie 1955 11 weeks
5 Queen bohemian Rhapsody 1975/76 & 1991/92 14 weeks
7 Whitney Houston i Will Always Love You 1992 10 weeks
3 Wet Wet Wet love Is All Around 1994 15 weeks
因此,它首先按大写字母排序,然后通过小写字母进行单独排序。我希望进行组合排序,不考虑Single列中起始字母的大小写。在排序后,“bohemian Rhapsody”所在的行位置不正确。它应该是第一个;而不是在排序后作为第5行出现。
是否有一种方法可以对Pandas DataFrame进行排序,同时忽略Single列文本的大小写?