我知道我的问题需要更多的指导而不是技术细节,但我希望SO的成员不会介意一个TPL Dataflow的新手问一些基本的问题。
我有一个简单的Windows Form应用程序,负责从我的系统中提取Excel文件数据并将其保存到数据库中。这个过程太长了,我想让它异步和并行化。下面是我的情况简述。
调用函数在开始时打开与数据库的连接。 调用函数更新操作时间的数据库。 应用程序需要处理假设100个按增量顺序排列的Excel文件。为此,我使用FileNumber来递增每个调用。 调用函数UpdateUI(传递PageNumber)(例如,正在处理文件1)。 调用函数Read Excel file(传递PageNumber)。 调用函数Process Excel file data(传递Excel Data和PageNumber)。 调用函数Save values in the database(传递Excel Data和PageNumber)。 调用函数UpdateUI(传递PageNumber)(例如,已处理文件1)。
现在我已经成功地使用Tasks使这个过程异步化。我对所有长时间运行的操作都使用了async和await,并将我的函数转换为任务。
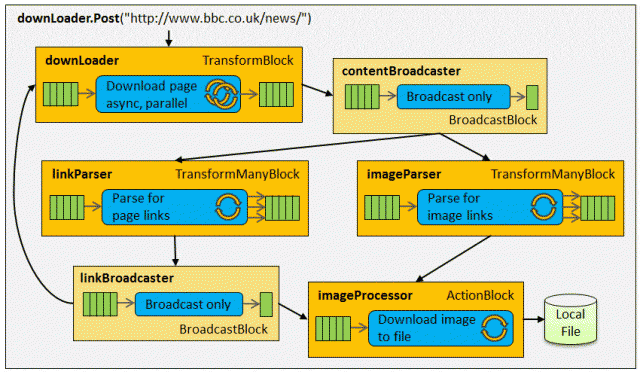
现在我想让一些任务并行运行。不是每个任务都会并行运行,例如OpenDatabase连接只是异步的。但我想创建一个单独的任务或函数,它将使用Dataflow块从更新UI到ReadingExcel文件和将它们保存到数据库的每个任务/函数中。
我开始使用ActionBlock尝试这个,但有许多不同的块我一无所知。请指导我在这种情况下将使用哪个块。如果有人能够为这种情况提供伪代码,那就太好了。我将有一个起点。
我有一个简单的Windows Form应用程序,负责从我的系统中提取Excel文件数据并将其保存到数据库中。这个过程太长了,我想让它异步和并行化。下面是我的情况简述。
调用函数在开始时打开与数据库的连接。 调用函数更新操作时间的数据库。 应用程序需要处理假设100个按增量顺序排列的Excel文件。为此,我使用FileNumber来递增每个调用。 调用函数UpdateUI(传递PageNumber)(例如,正在处理文件1)。 调用函数Read Excel file(传递PageNumber)。 调用函数Process Excel file data(传递Excel Data和PageNumber)。 调用函数Save values in the database(传递Excel Data和PageNumber)。 调用函数UpdateUI(传递PageNumber)(例如,已处理文件1)。
现在我已经成功地使用Tasks使这个过程异步化。我对所有长时间运行的操作都使用了async和await,并将我的函数转换为任务。
现在我想让一些任务并行运行。不是每个任务都会并行运行,例如OpenDatabase连接只是异步的。但我想创建一个单独的任务或函数,它将使用Dataflow块从更新UI到ReadingExcel文件和将它们保存到数据库的每个任务/函数中。
我开始使用ActionBlock尝试这个,但有许多不同的块我一无所知。请指导我在这种情况下将使用哪个块。如果有人能够为这种情况提供伪代码,那就太好了。我将有一个起点。