我试图使用系统资源来创建设计良好的TPL数据流管道。我的项目是一个HTML解析器,它将解析出的值添加到SQL Server数据库中。我已经拥有了未来管道的所有方法,现在我的问题是什么是最优的方式将它们放置在数据流块中,以及我应该使用多少个块?其中一些方法是CPU绑定,另一些方法是I/O绑定(从互联网加载,SQL Server DB查询)。目前,我认为将每个I/O操作放置在单独的块中就像在这个方案中是正确的:
在这种情况下,设计管道的基本规则是什么?
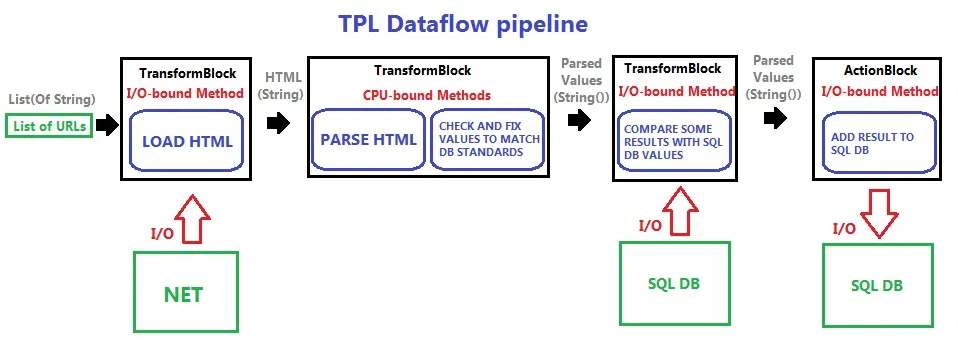
我试图使用系统资源来创建设计良好的TPL数据流管道。我的项目是一个HTML解析器,它将解析出的值添加到SQL Server数据库中。我已经拥有了未来管道的所有方法,现在我的问题是什么是最优的方式将它们放置在数据流块中,以及我应该使用多少个块?其中一些方法是CPU绑定,另一些方法是I/O绑定(从互联网加载,SQL Server DB查询)。目前,我认为将每个I/O操作放置在单独的块中就像在这个方案中是正确的:
在这种情况下,设计管道的基本规则是什么?
选择如何划分块的一种方法是决定您想要独立缩放哪些部分。一个好的起点是将CPU绑定部分与I/O绑定部分分开。考虑将最后两个块合并,因为它们都是I/O绑定(可能是到同一个数据库)。
public class Pipeline<TSource, TDest> : IPipeline
{
private readonly IPipelineStage[] _stages;
public Pipeline(Func<TSource, TDest> transform, int degree) :
this (new IPipelineStage[0], transform, degree) {}
internal Pipeline(IPipelineStage[] toCopy, Func<TSource, TDest> transform, int degree)
{
_stages = new IPipelineStage[toCopy.Length] + 1;
Array.Copy(toCopy, _stages, _stages.Length);
_stages[_stages.Length - 1] = new PipelineStage(transform, degree);
}
public Pipeline<TSource, TNew> AddStage<TNew>(Func<TDest, TNew> transform, degree)
{
return new Pipeline<TSource, TNew>(_stages, transform, degree);
}
public IEnumerator<TDest> GetEnumerator(IEnumerable<TSrouce> arg)
{
IEnumerable er = arg;
CountdownEvent ev = null;
for (int i = 0; i < _stages.Length; i++)
er = _stages[i].Start(er, ref ev);
foreach (TDest elem in ef)
yield return elem;
}
}
class PipelineStage<TInput, TOutput> : IPipelineStage
{
private readonly Func<TInput, TOutput> _transform;
private readonly int _degree;
internal PipelineStage(Func<TInput, TOutput> transform, int degree)
{
_transform = transform;
_degree = degree;
}
internal IEnumerable Start(IEnumerable src)
{
//...
}
}
interface IPipelineStage
{
IEnumerable Start(IEnumerable Src);
}