我有一个包含id信息的数据框df_a:
unique_id lacet_number
15 5570613 TLA-0138365
24 5025490 EMP-0138757
36 4354431 DXN-0025343
还有另一个数据框 df_b,行数与我知道对应于df_a中的行数相同:
latitude longitude
0 -93.193560 31.217029
1 -93.948082 35.360874
2 -103.131508 37.787609
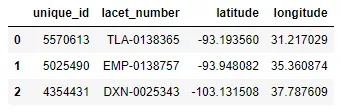
cbind),得到如下结果: unique_id lacet_number latitude longitude
0 5570613 TLA-0138365 -93.193560 31.217029
1 5025490 EMP-0138757 -93.948082 35.360874
2 4354431 DXN-0025343 -103.131508 37.787609
我尝试过的:
df_c = pd.concat([df_a, df_b], axis=1)
这使我得到了一个外连接。
unique_id lacet_number latitude longitude
0 NaN NaN -93.193560 31.217029
1 NaN NaN -93.948082 35.360874
2 NaN NaN -103.131508 37.787609
15 5570613 TLA-0138365 NaN NaN
24 5025490 EMP-0138757 NaN NaN
36 4354431 DXN-0025343 NaN NaN
问题在于两个数据帧的索引不匹配。我阅读了pandas.concat 的文档,并看到有一个 ignore_index 选项。但这只适用于连接轴,而我这里是行,所以这肯定不是正确的选择。那么我的问题是:有没有简单的方法可以解决这个问题?
cbind()是一个R函数,它通过列(pd.concat(..., axis=1))来连接数据框和/或序列('向量')。然而,pandas的concat()尝试对齐索引,而R的cbind()则忽略它们。 - undefined