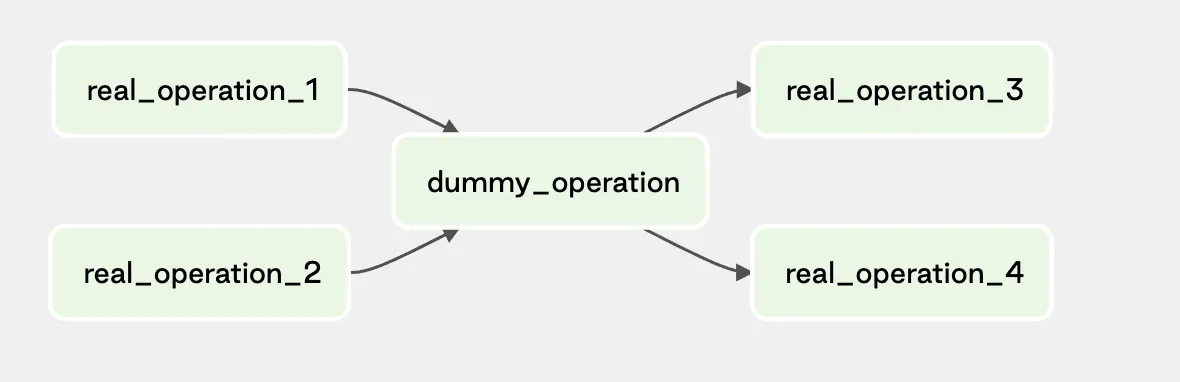
我对Apache Airflow和DAG还不熟悉。DAG中一共有6个任务(task1, task2, task3, task4, task5, task6)。但在运行DAG时,我们遇到了以下错误:
DAG unsupported operand type(s) for >>: 'list' and 'list'
下面是我用于DAG的代码,请帮忙看看。我是Airflow的新手。
from airflow import DAG
from datetime import datetime
from airflow.providers.databricks.operators.databricks import DatabricksSubmitRunOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False
}
dag = DAG('DAG_FOR_TEST',default_args=default_args,schedule_interval=None,max_active_runs=3, start_date=datetime(2020, 7, 14))
#################### CREATE TASK #####################################
task_1 = DatabricksSubmitRunOperator(
task_id='task_1',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_1/task_1.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_1.driver.TestClass1',
'parameters' : [
'{{ dag_run.conf.json }}'
]
}
)
task_2 = DatabricksSubmitRunOperator(
task_id='task_2',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_2/task_2.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_2.driver.TestClass2',
'parameters' : [
'{{ dag_run.conf.json }}'
]
}
)
task_3 = DatabricksSubmitRunOperator(
task_id='task_3',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_3/task_3.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_3.driver.TestClass3',
'parameters' : [
'{{ dag_run.conf.json }}'
]
}
)
task_4 = DatabricksSubmitRunOperator(
task_id='task_4',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_4/task_4.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_4.driver.TestClass4',
'parameters' : [
'{{ dag_run.conf.json }}'
]
}
)
task_5 = DatabricksSubmitRunOperator(
task_id='task_5',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_5/task_5.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_5.driver.TestClass5',
'parameters' : [
'json ={{ dag_run.conf.json }}'
]
}
)
task_6 = DatabricksSubmitRunOperator(
task_id='task_6',
databricks_conn_id='connection_id_details',
existing_cluster_id='{{ dag_run.conf.clusterId }}',
libraries= [
{
'jar': 'dbfs:/task_6/task_6.jar'
}
],
spark_jar_task={
'main_class_name': 'com.task_6.driver.TestClass6',
'parameters' : ['{{ dag_run.conf.json }}'
]
}
)
#################### ORDER OF OPERATORS ###########################
task_1.dag = dag
task_2.dag = dag
task_3.dag = dag
task_4.dag = dag
task_5.dag = dag
task_6.dag = dag
task_1 >> [task_2 , task_3] >> [ task_4 , task_5 ] >> task_6