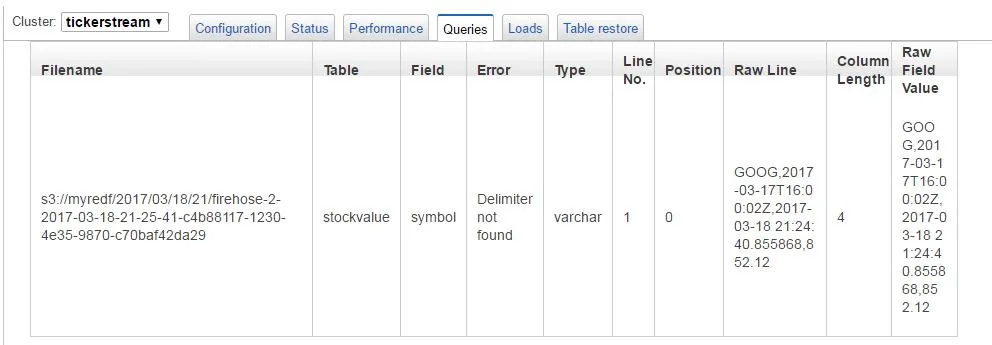
我将使用Kinesis Firehose通过S3将数据传输到Redshift。我有一个非常简单的csv文件,看起来像这样。Firehose将其放入S3中,但Redshift出现了分隔符未找到的错误。我查看了与此错误相关的所有帖子,但我确保包含了分隔符。
文件
GOOG,2017-03-16T16:00:01Z,2017-03-17 06:23:56.986397,848.78
GOOG,2017-03-16T16:00:01Z,2017-03-17 06:24:02.061263,848.78
GOOG,2017-03-16T16:00:01Z,2017-03-17 06:24:07.143044,848.78
GOOG,2017-03-16T16:00:01Z,2017-03-17 06:24:12.217930,848.78
或者
"GOOG","2017-03-17T16:00:02Z","2017-03-18 05:48:59.993260","852.12"
"GOOG","2017-03-17T16:00:02Z","2017-03-18 05:49:07.034945","852.12"
"GOOG","2017-03-17T16:00:02Z","2017-03-18 05:49:12.306484","852.12"
"GOOG","2017-03-17T16:00:02Z","2017-03-18 05:49:18.020833","852.12"
"GOOG","2017-03-17T16:00:02Z","2017-03-18 05:49:24.203464","852.12"
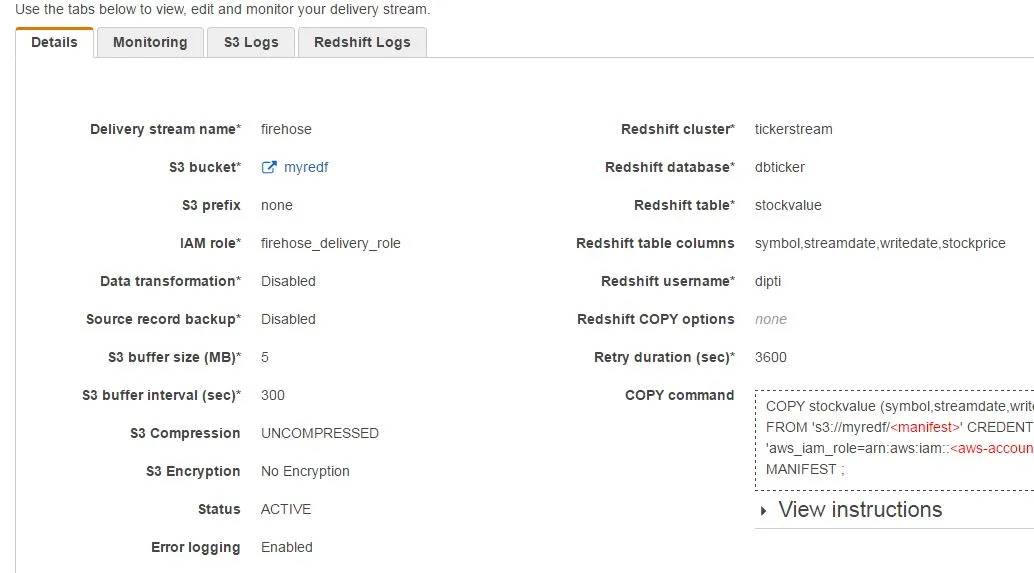
Redshift表
CREATE TABLE stockvalue
( symbol VARCHAR(4),
streamdate VARCHAR(20),
writedate VARCHAR(26),
stockprice VARCHAR(6)
);
{kind=link}
{kind=link}
有人能指出文件可能存在什么问题吗? 我在字段之间添加了逗号。 目标表中的所有列都是 varchar 类型,因此不应该出现数据类型错误。 此外,文件和 Redshift 表之间的列长度完全相同。 我尝试过用双引号嵌入列,也尝试过不用。