我想将以parquet格式的数据从Kinesis Firehose导入S3。到目前为止,我只找到了一个需要创建EMR的解决方案,但我正在寻找更便宜和更快的方式,比如直接从Firehose将接收到的JSON存储为parquet,或者使用Lambda函数。
非常感谢, Javi。
我想将以parquet格式的数据从Kinesis Firehose导入S3。到目前为止,我只找到了一个需要创建EMR的解决方案,但我正在寻找更便宜和更快的方式,比如直接从Firehose将接收到的JSON存储为parquet,或者使用Lambda函数。
非常感谢, Javi。
好消息,此功能今天发布了!
Amazon Kinesis Data Firehose可以在将数据存储到Amazon S3之前,将输入数据的格式从JSON转换为Apache Parquet或Apache ORC。Parquet和ORC是列式数据格式,可节省空间并加快查询速度。
要启用,请转到您的Firehose流并单击编辑。您应该会看到如下屏幕截图所示的记录格式转换部分:
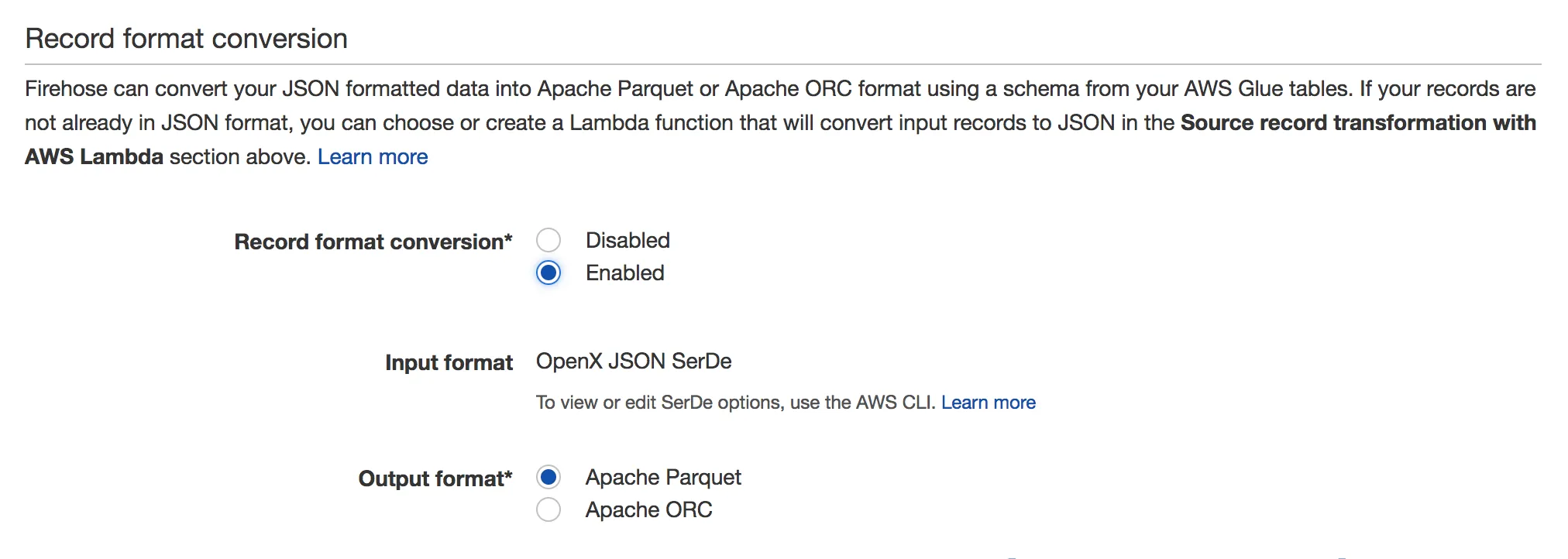
有关详细信息,请参阅文档:https://docs.aws.amazon.com/firehose/latest/dev/record-format-conversion.html
在使用AWS支持服务和数百个不同的实现之后,我想解释一下我取得了什么成果。
最终,我创建了一个Lambda函数来处理由Kinesis Firehose生成的每个文件,根据负载对我的事件进行分类,并将结果存储在S3中的Parquet文件中。
这并不容易:
首先,您应该创建一个Python虚拟环境,其中包括所有所需的库(在我的情况下为Pandas、NumPy、Fastparquet等)。由于生成的文件(其中包括所有库和我的Lambda函数)很大,因此需要启动EC2实例,我已经使用了免费层中提供的实例。按照以下步骤创建虚拟环境:
正确创建lambda_function:
import json
import boto3
import datetime as dt
import urllib
import zlib
import s3fs
from fastparquet import write
import pandas as pd
import numpy as np
import time
def _send_to_s3_parquet(df):
s3_fs = s3fs.S3FileSystem()
s3_fs_open = s3_fs.open
# FIXME add something else to the key or it will overwrite the file
key = 'mybeautifullfile.parquet.gzip'
# Include partitions! key1 and key2
write( 'ExampleS3Bucket'+ '/key1=value/key2=othervalue/' + key, df,
compression='GZIP',open_with=s3_fs_open)
def lambda_handler(event, context):
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'])
try:
s3 = boto3.client('s3')
response = s3.get_object(Bucket=bucket, Key=key)
data = response['Body'].read()
decoded = data.decode('utf-8')
lines = decoded.split('\n')
# Do anything you like with the dataframe (Here what I do is to classify them
# and write to different folders in S3 according to the values of
# the columns that I want
df = pd.DataFrame(lines)
_send_to_s3_parquet(df)
except Exception as e:
print('Error getting object {} from bucket {}.'.format(key, bucket))
raise e
将lambda函数复制到lambda.zip,并部署lambda_function:
在需要时触发执行,例如每次在S3中创建新文件,甚至可以将lambda函数关联到Firehose。(我没有选择此选项,因为'lambda'限制比Firehose限制低,您可以将Firehose配置为每128Mb或15分钟写入一个文件,但如果将此lambda函数关联到Firehose,则每3分钟或5MB执行一次该lambda函数,在我的情况下,我遇到了生成大量小parquet文件的问题,因为每次启动lambda函数时,我至少会生成10个文件)。
Amazon Kinesis Firehose接收流记录并可以将它们存储在Amazon S3(或Amazon Redshift或Amazon Elasticsearch Service)中。
每个记录可以最多达到1000KB。
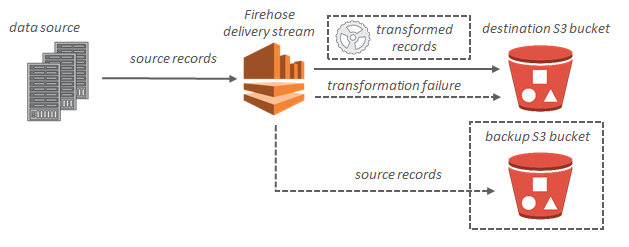
但是,记录会被附加在一起形成文本文件,并根据时间或大小进行分批处理。传统上,记录采用JSON格式。
您将无法发送parquet文件,因为它不符合此文件格式。
触发Lambda数据转换功能是可能的,但它也不能输出parquet文件。
事实上,考虑到parquet文件的性质,很难逐条构建它们。作为列存储格式,它们似乎确实需要批量创建,而不是每条记录追加数据。
底线:不行。