我认为这个话题非常重要和有趣。我想扩展上述答案:
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
from scipy.misc import derivative
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,\
16,17,18,19,20,21,22,23,24,25,26,27,28,29,30])
y = np.array([2,5,7,9,10,13,16,18,21,22,21,20,19,18,\
17,14,10,9,7,5,7,9,10,12,13,15,16,17,22,27])
f = interp1d(x, y, fill_value="extrapolate")
x_fake = np.arange(1.1, 30, 0.1)
df_dx = derivative(f, x_fake, dx=1e-6)
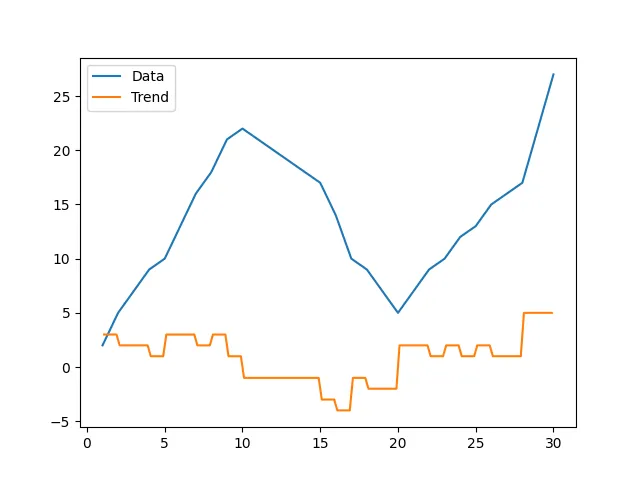
plt.plot(x,y, label = "Data")
plt.plot(x_fake,df_dx,label = "Trend")
plt.legend()
plt.show()
average = np.average(df_dx)
if average > 0 :
print("Uptrend", average)
elif average < 0:
print("Downtrend", average)
elif average == 0:
print("No trend!", average)
print("Max trend measure is:")
print(np.max(df_dx))
print("min trend measure is:")
print(np.min(df_dx))
print("Overall trend measure:")
print(((np.max(df_dx))-np.min(df_dx)-average)/((np.max(df_dx))-np.min(df_dx)))
extermum_list_y = []
extermum_list_x = []
for i in range(0,df_dx.shape[0]):
if df_dx[i] < 0.001 and df_dx[i] > -0.001:
extermum_list_x.append(x_fake[i])
extermum_list_y.append(df_dx[i])
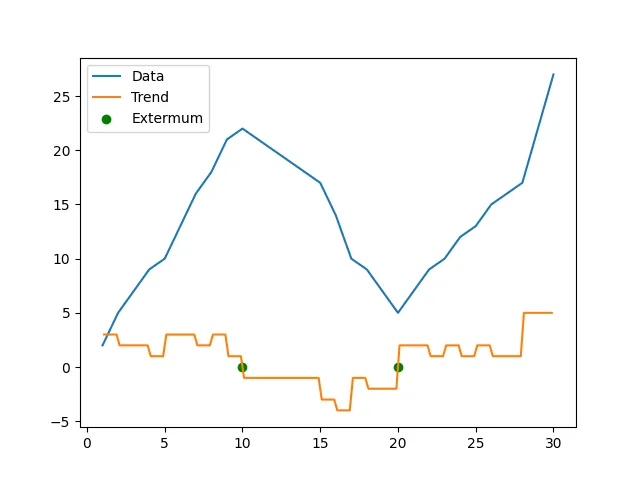
plt.scatter(extermum_list_x, extermum_list_y, label="Extermum", marker = "o", color = "green")
plt.plot(x,y, label = "Data")
plt.plot(x_fake, df_dx, label="Trend")
plt.legend()
plt.show()
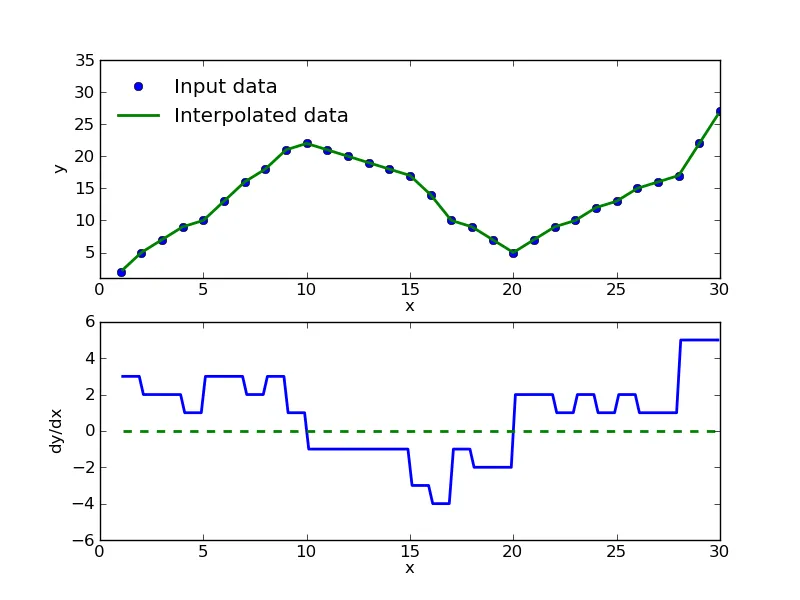
因此,总体趋势是上升的!当您想要找到斜率为零的x时,这种方法也很好;例如,曲线中的极值。局部最小值和最大值点可以以最佳精度和计算时间找到。