在我的业余时间里,我试图提高自己在预测技术方面的能力。今天的问题集中在使用多个回归变量进行预测。我创建了一个受两个回归变量影响的时间序列,但不确定如何使用它们进行预测。
library(forecast)
我尝试了以下方法:
首先是我的时间序列:
ts.series3 <- structure(c(313, 253, 230, 258, 261, 303, 266, 269, 245, 274,
346, 252, 283, 286, 260, 365, 295, 268, 301, 304, 353, 310, 313,
285, 319, 403, 294, 330, 333, 303, 425, 343, 312, 350, 354, 411,
361, 366, 333, 469, 380, 346, 487, 394, 359, 404, 511, 372, 418
), .Tsp = c(2003.08333333333, 2007.08333333333, 12), class = "ts")
上述时间序列基于下面展示的趋势ts.trend并通过修饰器进行修改。如果第一个修饰器适用,则值增加25%,如果适用于第二个修饰器,则值减少10%。当两者都适用时,则增加15%。
ts.trend <- structure(c(250, 253, 255, 258, 261, 264, 266, 269, 272, 274,
277, 280, 283, 286, 289, 292, 295, 298, 301, 304, 307, 310, 313,
316, 319, 323, 326, 330, 333, 337, 340, 343, 347, 350, 354, 357,
361, 366, 370, 375, 380, 385, 390, 394, 399, 404, 409, 414, 418
), .Tsp = c(2003.08333333333, 2007.08333333333, 12), class = "ts")
一种带有两个回归变量的多元时间序列:
modifiers <- structure(c(1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0,
0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0), .Dim = c(60L,
2L), .Dimnames = list(NULL, c("Adjust1", "Adjust2")), .Tsp = c(2003.08333333333,
2008, 12), class = c("mts", "ts"))
然后我尝试制作以下模型:
fit.series3 <- auto.arima(ts.series3,xreg=window(modifiers,end=2007.16))
fcast.series3 <- forecast(fit.series3,xreg=window(modifiers,start=2007.161))
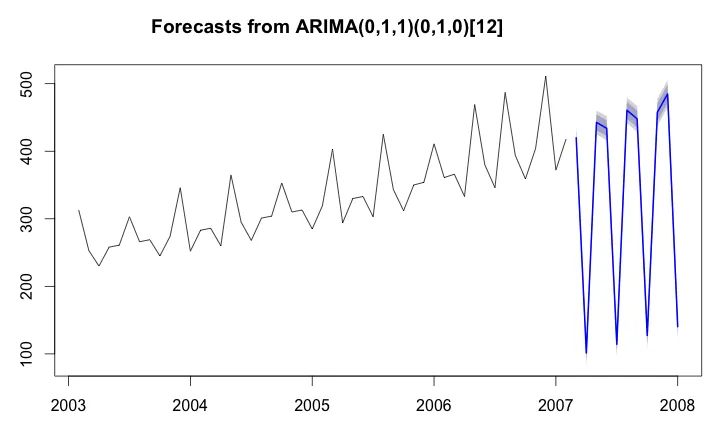
代码似乎运行良好,但图表(见下文)不是很有意义,因为没有识别到回归器,你会期望预测更多地遵循趋势线。有人能提供一些关于这里发生了什么的见解吗?
plot(fcast.series3)
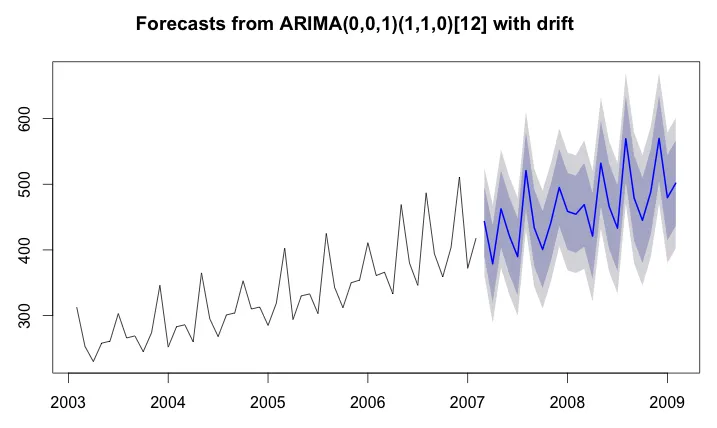
如果我不使用任何回归变量,预测图看起来如下所示。与上面的图相比,我更有信心这个预测结果。我使用了以下代码生成图表:
fit.series3clean <- auto.arima(ts.series3)
fcast.series3clean <- forecast(fit.series3clean)
plot(fcast.series3clean)
我想知道有没有人能理解我的多元xreg值预测发生了什么。此外,我也很想听听其他使用多元回归器进行预测的方法。
Adjust2中的s.e.最终变成了NaN。 - Jochem