我还没有找到适用于我的问题的答案,所以我来提问:
我有一个图像的初始数据框,我想根据该图像的描述(即“Description”列中的字符串)将其分成两部分。
我的问题是,并非所有描述都是相同的。以下是我所说的例子:
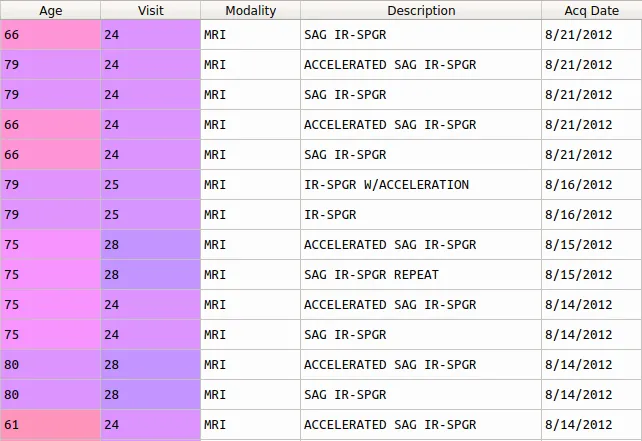
有些图像加速,有些则不是。这就是我想要使用的标准来分割数据集。
然而,即使是加速和非加速图像的描述也各不相同。
我的策略是将每个包含“ACC”的字符串重命名为“ACCELERATED IMAGE” - 这将覆盖所有加速图像。
然后我可以执行以下操作:
df_Accl = df[df.Description == "ACCELERATED IMAGE"]
df_NonAccl = df[df.Description != "ACCELERATED IMAGE"]
我该如何实现这个目标?这只是我想出的一种策略,如果有更高效的方法,请随意提出。