我有一个数组,我想查看该数组中的任何元素是否大于或等于该数组中的其他任何元素。我可以使用两个for循环来实现,但是我的数组长度为10,000或更长,因此这会创建一个非常缓慢的程序。有没有什么方法可以更快地完成这个任务?
[编辑] 我只需要查看它是否大于或等于我正在查看的元素后面的元素,如果是,则需要知道它的索引。
[编辑] 我将重新解释我的问题,因为当前的解决方案不适用于我所需要的内容。首先,这是一些代码。
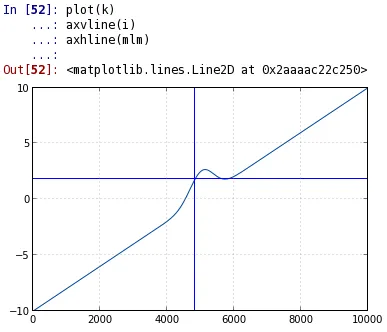
所以,我有一个x数组,通过将其放入高斯函数来获取其高度,然后基于该高度,这是x值通过空间传播的速度,在此我使用k来找到。我的问题是,我需要找到高斯函数变为双值函数的时候(或换句话说,发生激波时)。如果我使用argmax解决方案,我总是会得到k中的最后一个值,因为它非常接近零,我需要在元素之后的第一个值,这将为我提供双值函数。
[编辑]小例子
[编辑] 我只需要查看它是否大于或等于我正在查看的元素后面的元素,如果是,则需要知道它的索引。
[编辑] 我将重新解释我的问题,因为当前的解决方案不适用于我所需要的内容。首先,这是一些代码。
x=linspace(-10, 10, 10000)
t=linspace(0,5,10000)
u=np.exp(-x**2)
k=u*t+x
所以,我有一个x数组,通过将其放入高斯函数来获取其高度,然后基于该高度,这是x值通过空间传播的速度,在此我使用k来找到。我的问题是,我需要找到高斯函数变为双值函数的时候(或换句话说,发生激波时)。如果我使用argmax解决方案,我总是会得到k中的最后一个值,因为它非常接近零,我需要在元素之后的第一个值,这将为我提供双值函数。
[编辑]小例子
x=[0,1,2,3,4,5,6,7,8,9,10] #Input
k=[0,1,2,3,4,5,6,5,4,10] #adjusted for speed
output I want
in this case, 5 is the first number that goes above a number that comes after it.
So I need to know the index of where 5 is located and possibly the index
of the number that it is greater than
A和索引I,确定A[I]是否大于A中所有后续值。如果不是,则确定A中最大后续值的索引。这样对吗? - Robᵩ