MySQL,PostgreSQL和MS SQL Server是关系型数据库系统,而NoSQL、MongoDB等则是非关系型数据库管理系统。
这两种类型的系统有什么区别?
MySQL,PostgreSQL和MS SQL Server是关系型数据库系统,而NoSQL、MongoDB等则是非关系型数据库管理系统。
这两种类型的系统有什么区别?
你所谓的“知识”大部分都是错误的。
首先,正如一些关系数据库专家经常(有时甚至强烈地)指出的那样,SQL与关系理论的适配程度并不像许多人想象的那样紧密。其次,“NoSQL”中的大部分差异与是否关系型关系不大。最后,“NoSQL”与SQL之间的区别很难确定,因为它们两者都代表了广泛的可能性。
你可以确定的一个主要区别是,支持SQL的几乎所有东西都支持在数据库本身中设置触发器 - 也就是说,你可以将规则设计到数据库中,以确保数据始终保持内部一致性。例如,你可以设置数据库来断言一个人必须具有地址。如果这样做,每当你添加一个人时,它基本上会强制你将该人物与某个地址相关联。你可以添加一个新地址,或者将他们与某个现有地址相关联,但无论如何,该人必须有一个地址。同样,如果你删除一个地址,它会强制你要么删除当前该地址下的所有人员,要么将每个人与其他地址相关联。你还可以对其他关系进行类似的操作,比如说每个人必须有一个母亲,每个办公室必须有一个电话号码等。
需要注意的是,这些操作也保证会以原子方式进行,因此如果其他人在你添加人员时查看数据库,他们将要么根本看不到该人员,要么看到该人员与地址(或母亲等)一起出现。
大多数NoSQL数据库并不试图在数据库本身提供此类强制执行。在使用数据库的代码中,需要你自己强制执行数据必需的任何关系。在大多数情况下,也可能会看到只有部分正确的数据,因此即使你有一个家族谱,每个人都应该与父母相关联,仍然可能存在某些约束条件无法得到真正执行的情况。有些数据库允许你随意这样做,而另一些则保证它仅是暂时性的,尽管它可能的持续时间有待商榷。
{
"id":"XXX",
"user":"XXX",
"date":"xxxx-xx-xx",
"content":{
"text":"XXXX",
"picture":["p1.png","p2.png","p3.png"]
}
CREATE TABLE products (
product_no integer,
name text,
price numeric
);
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99);
让我们看另一个不同的例子:
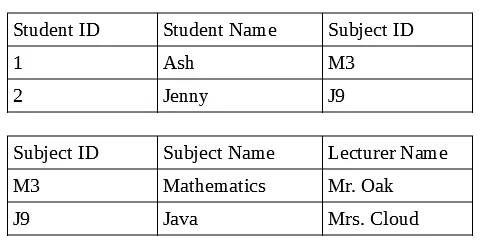
在关系型数据库中,我们可以使用外键、课程ID等关系将学生表和课程表连接起来。但在非关系型数据库中,由于没有关系,不需要两个文档,因此我们将所有课程详情和学生详情存储在一个文档中,即学生文档,这样会导致数据重复,使记录更新变得麻烦。
在非关系型数据库中,没有固定的模式,数据未经规范化。没有创建数据之间的关系,所有数据大多数都放在一个文档中。处理大量数据时非常适用,并且可以一次传输大量数据,最适合高读取量和低写入量以及较少的更新,但查询数据有些困难,因为没有固定的模式。水平和垂直扩展均可行。符合CAP(一致性、可用性、分区容错)和BASE(基本可用、软状态、最终一致性)标准。
让我演示一个使用Mongodb向非关系型数据库输入数据的例子。
db.users.insertOne({name: ‘Mary’, age: 28 , occupation: ‘writer’ })
db.users.insertOne({name: ‘Ben’ , age: 21})
({Studname: ‘Ash’, Subname: ‘Mathematics’, LecturerName: ‘Mr. Oak’})
{kind=link}