我想执行这个操作:
 如果
如果  有一个规则的形状,那么我可以使用np.einsum,我相信语法应该是:
有一个规则的形状,那么我可以使用np.einsum,我相信语法应该是:
很不幸,我的数据X在第一(如果我们从零索引)轴上具有非常规结构。
为了更好地说明, 指的是第i组中第j个成员的第p个特征。由于不同组大小不同,因此实际上它是一个长度不同的列表的列表,每个列表的长度相同。
指的是第i组中第j个成员的第p个特征。由于不同组大小不同,因此实际上它是一个长度不同的列表的列表,每个列表的长度相同。
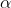 具有规则结构,因此可以保存为标准的numpy数组(它首先是1维的,然后我使用alpha.reshape(a,b,c),其中a,b,c是问题特定的整数)。
具有规则结构,因此可以保存为标准的numpy数组(它首先是1维的,然后我使用alpha.reshape(a,b,c),其中a,b,c是问题特定的整数)。
我想避免将X存储为列表的列表或不同维度的np.array列表,并编写类似以下内容的代码:
np.einsum('ijp,ipk->ijk',X, alpha)
很不幸,我的数据X在第一(如果我们从零索引)轴上具有非常规结构。
为了更好地说明,
我想避免将X存储为列表的列表或不同维度的np.array列表,并编写类似以下内容的代码:
A = []
for i in range(num_groups):
temp = np.empty(group_sizes[i], dtype=float)
for j in range(group_sizes[i]):
temp[i] = np.einsum('p,pk->k',X[i][j], alpha[i,:,:])
A.append(temp)
有没有一些不错的numpy函数或数据结构可以用来完成这个操作?或者我必须妥协,采用部分向量化的实现方式?