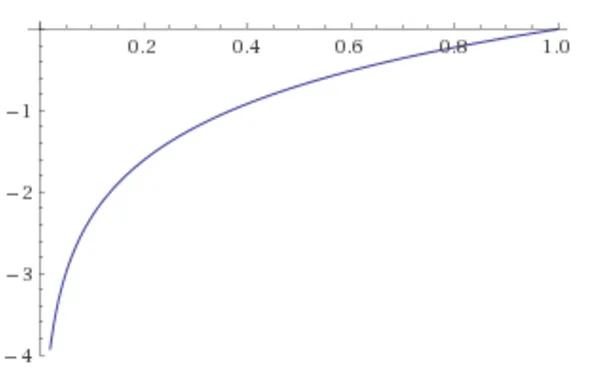
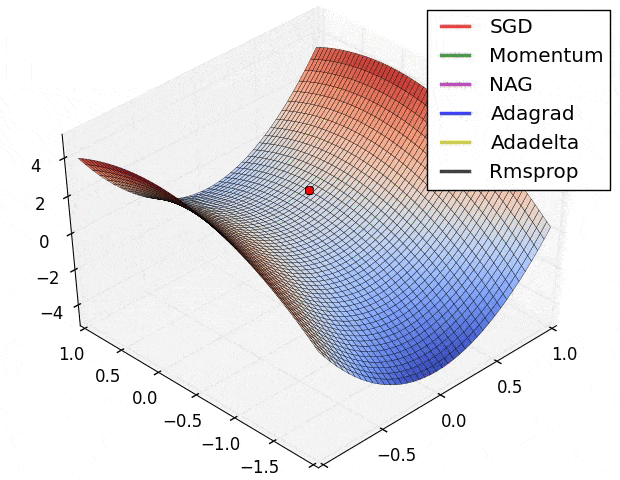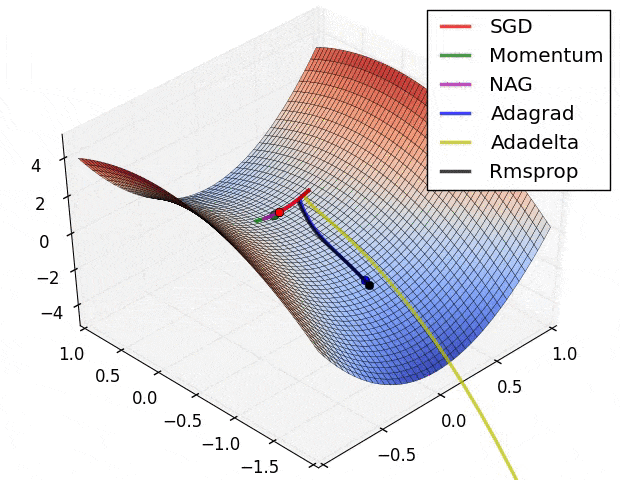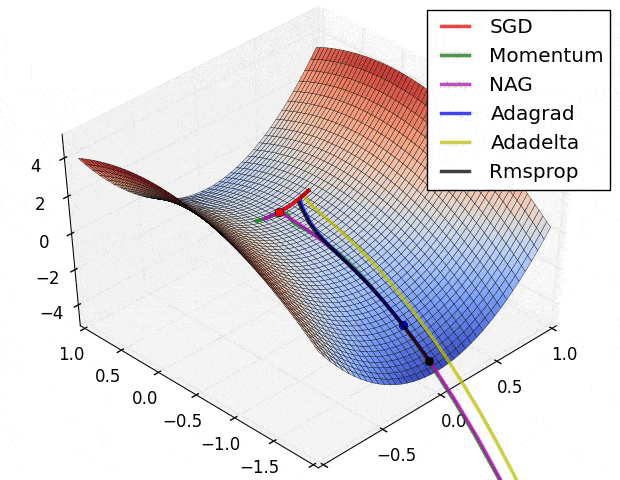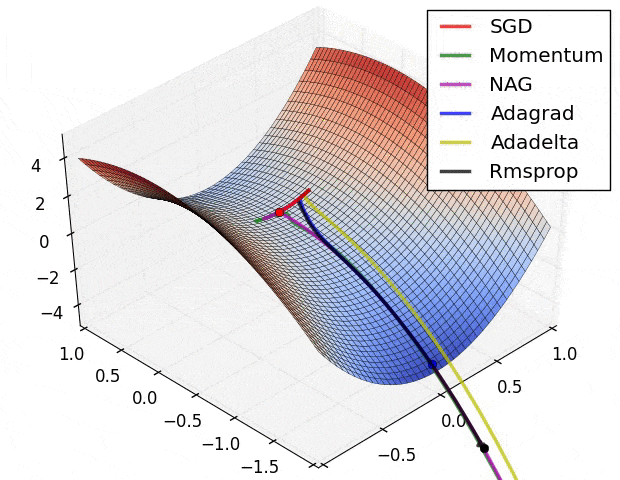
我创建了一个有两个RELU隐藏层 + 线性激活层的ANN,并尝试近似简单的ln(x)函数。但我做得不好。我感到困惑,因为在x:[0.0-1.0]范围内的ln(x)应该没有问题地进行逼近(我使用学习率0.01和基本梯度下降优化)。
import tensorflow as tf
import numpy as np
def GetTargetResult(x):
curY = np.log(x)
return curY
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# # Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# Parameters
learning_rate = 0.01
training_epochs = 10000
batch_size = 50
display_step = 500
# Network Parameters
n_hidden_1 = 50 # 1st layer number of features
n_hidden_2 = 10 # 2nd layer number of features
n_input = 1
# Store layers weight & bias
weights = {
'h1': tf.Variable(tf.random_uniform([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_uniform([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_uniform([n_hidden_2, 1]))
}
biases = {
'b1': tf.Variable(tf.random_uniform([n_hidden_1])),
'b2': tf.Variable(tf.random_uniform([n_hidden_2])),
'out': tf.Variable(tf.random_uniform([1]))
}
x_data = tf.placeholder(tf.float32, [None, 1])
y_data = tf.placeholder(tf.float32, [None, 1])
# Construct model
pred = multilayer_perceptron(x_data, weights, biases)
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(pred - y_data))
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables ()
# Launch the graph.
sess = tf.Session()
sess.run(init)
for step in range(training_epochs):
x_in = np.random.rand(batch_size, 1).astype(np.float32)
y_in = GetTargetResult(x_in)
sess.run(train, feed_dict = {x_data: x_in, y_data: y_in})
if(step % display_step == 0):
curX = np.random.rand(1, 1).astype(np.float32)
curY = GetTargetResult(curX)
curPrediction = sess.run(pred, feed_dict={x_data: curX})
curLoss = sess.run(loss, feed_dict={x_data: curX, y_data: curY})
print("For x = {0} and target y = {1} prediction was y = {2} and squared loss was = {3}".format(curX, curY,curPrediction, curLoss))
对于上述配置,NN只是在学习猜测y=-1.00。我尝试了不同的学习率、优化器和不同的配置,但都没有成功——在任何情况下学习都无法收敛。我以前在其他深度学习框架中使用类似对数函数的方式,没有问题。这是TF特定的问题吗?我做错了什么?