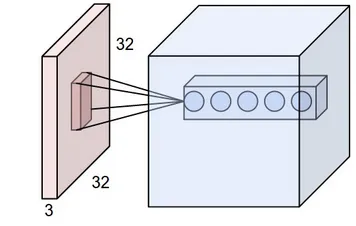
我正在阅读来自 CS231n Convolutional Neural Networks for Visual Recognition 的卷积神经网络。在卷积神经网络中,神经元按三个维度(
在链接中,他们说
例如,请看这张图片。如果图片太糟糕了,请见谅。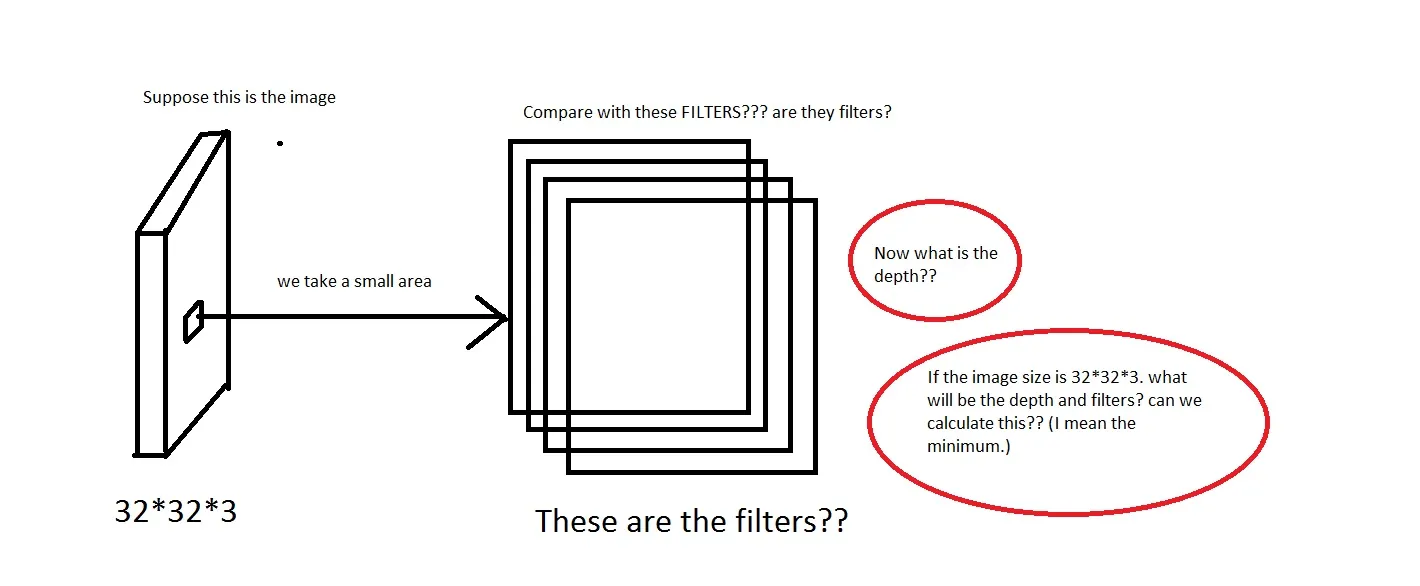 我能理解我们从图像中取一个小区域,然后与“过滤器”进行比较的想法。那么过滤器将是一组小图像吗?他们还说:“我们仅将每个神经元连接到输入体积的局部区域。这种连接的空间范围是称为神经元感受野的超参数。”那么感受野是否具有与过滤器相同的维度?在这里深度是多少?使用CNN的深度表示什么意思?
我能理解我们从图像中取一个小区域,然后与“过滤器”进行比较的想法。那么过滤器将是一组小图像吗?他们还说:“我们仅将每个神经元连接到输入体积的局部区域。这种连接的空间范围是称为神经元感受野的超参数。”那么感受野是否具有与过滤器相同的维度?在这里深度是多少?使用CNN的深度表示什么意思?
所以,我的问题主要是,如果我拿一个尺寸为
如果有人能提供一些关于此的直觉链接,那将非常有帮助。
编辑: 在教程的一个部分(现实世界的例子部分),它说:
这意味着深度会像这样吗?如果是这样,那么我可以假设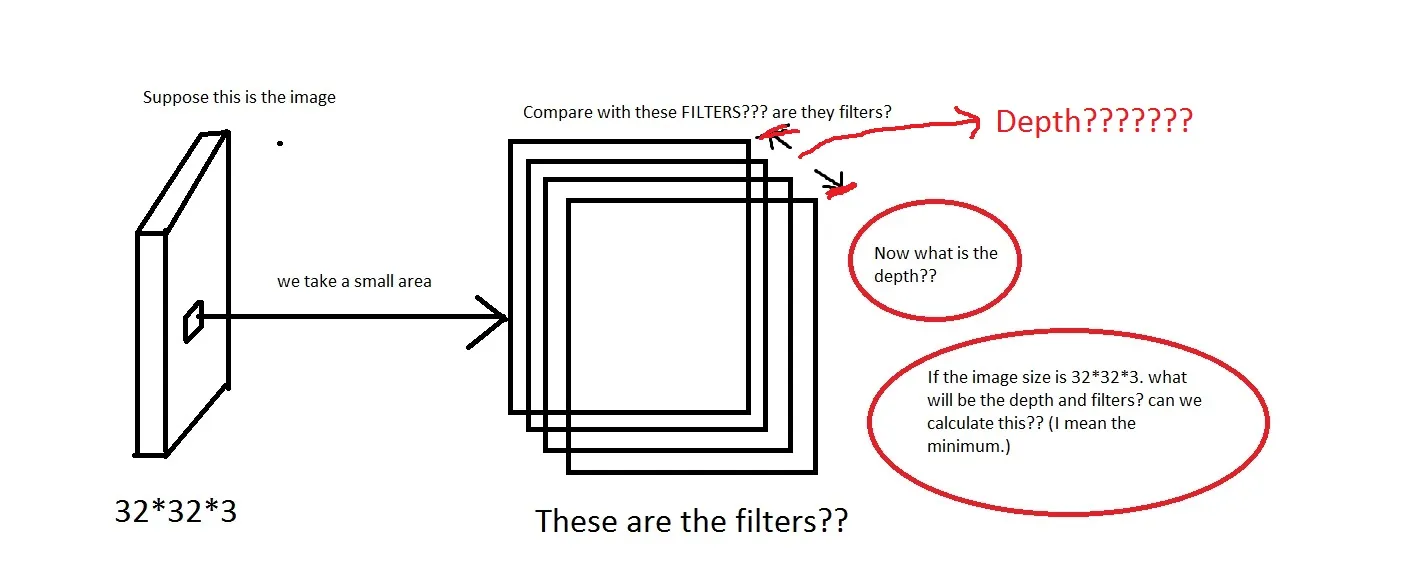
height,width,depth)排列。我无法想象出卷积神经网络中的depth是什么。在链接中,他们说
CONV层的参数由一组可学习的过滤器组成。每个过滤器在空间上很小(沿宽度和高度),但延伸到输入体的全部深度。 例如,请看这张图片。如果图片太糟糕了,请见谅。
我能理解我们从图像中取一个小区域,然后与“过滤器”进行比较的想法。那么过滤器将是一组小图像吗?他们还说:“我们仅将每个神经元连接到输入体积的局部区域。这种连接的空间范围是称为神经元感受野的超参数。”那么感受野是否具有与过滤器相同的维度?在这里深度是多少?使用CNN的深度表示什么意思?所以,我的问题主要是,如果我拿一个尺寸为
[32 * 32 * 3]的图像(假设我有50000个这样的图像,使数据集为[50000 * 32 * 32 * 3]),我应该选择什么作为它的深度,深度意味着什么。过滤器的尺寸是多少?如果有人能提供一些关于此的直觉链接,那将非常有帮助。
编辑: 在教程的一个部分(现实世界的例子部分),它说:
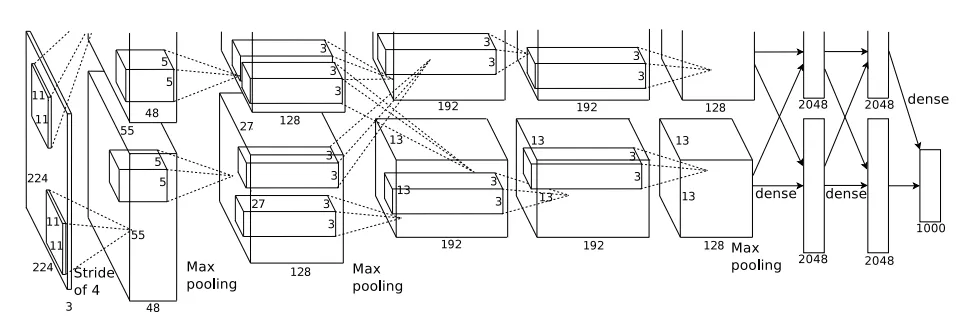
The Krizhevsky et al. architecture that won the ImageNet challenge in 2012 accepted images of size [227x227x3]. On the first Convolutional Layer, it used neurons with receptive field size F=11, stride S=4 and no zero padding P=0. Since (227 - 11)/4 + 1 = 55, and since the Conv layer had a depth of K=96, the Conv layer output volume had size [55x55x96].
我们可以看到深度是96。那么深度是我随意选择的吗?还是我计算出来的?另外,在上面的例子中(Krizhevsky等人),他们有96个深度。那么它的96个深度是什么意思? 教程还指出:Every filter is small spatially (along width and height), but extends through the full depth of the input volume。这意味着深度会像这样吗?如果是这样,那么我可以假设
Depth = Number of Filters吗?