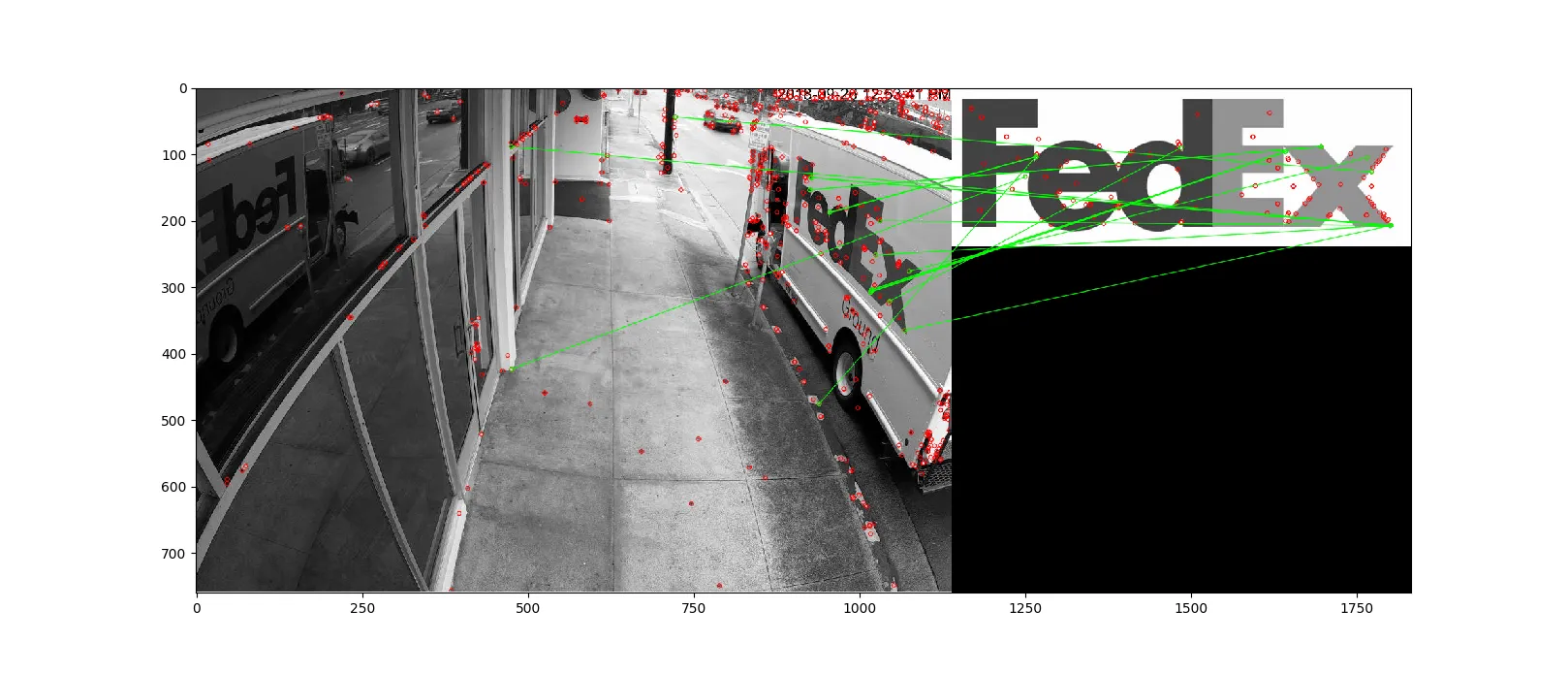
我一直在从事涉及图像处理的项目,用于标志检测。具体来说,目标是开发一个实时FedEx卡车/标志检测器的自动化系统,该系统从IP摄像机流中读取帧并在检测到标志时发送通知。以下是系统运行的示例,识别出的标志被绿色矩形框起来。


项目的一些限制:
- 使用原始OpenCV(没有深度学习、人工智能或训练好的神经网络)
- 图像背景可能嘈杂
- 图像亮度可能会有很大变化(早晨、下午、晚上)
- FedEx卡车/标志可以具有任何比例、旋转或方向,因为它可以停在人行道上的任何地方
- 标志可能会因为时间不同而模糊或模糊,颜色也不同
- 同一帧中可能会有许多其他大小或颜色相似的车辆
- 实时检测(从IP摄像头约25 FPS)
- IP摄像头处于固定位置,FedEx卡车始终处于相同的方向(不会倒置或颠倒)
- Fedex卡车始终是“红色”版本,而不是“绿色”版本
当前的实现/算法
我有两个线程:- 线程 #1 - 使用
cv2.VideoCapture()从IP摄像机捕获帧并调整帧大小以进行进一步处理。决定在单独的线程中处理抓取帧,以通过减少I/O延迟来提高FPS,因为cv2.VideoCapture()是阻塞的。通过专门为捕获帧分配一个独立的线程,这将允许主处理线程始终可以对其执行检测。 - 线程 #2 - 主处理/检测线程,使用颜色阈值和轮廓检测来检测FedEx标志。
For each frame:
Find bounding box for purple color of logo
Find bounding box for red/orange color of logo
If both bounding boxes are valid/adjacent and contours pass checks:
Combine bounding boxes
Draw combined bounding boxes on original frame
Play sound notification for detected logo
用颜色阈值法进行标志检测
为了进行颜色阈值处理,我已经定义了HSV(低、高)阈值来检测紫色和红色的标志。
colors = {
'purple': ([120,45,45], [150,255,255]),
'red': ([0,130,0], [15,255,255])
}
为了找到每个颜色的边界框坐标,我遵循以下算法:
- 模糊帧
- 使用内核侵蚀和膨胀帧以消除背景噪声
- 将帧从BGR转换为HSV颜色格式
- 使用设置的颜色阈值对帧执行掩码
- 在掩码中查找最大轮廓并获取边界坐标


假阳性检查
现在我有了两个掩码,我要进行检查以确保找到的边界框实际上形成了一个标志。为此,我使用cv2.matchShapes()比较两个轮廓并返回显示相似度的指标。结果越低,匹配度越高。此外,我还使用cv2.pointPolygonTest()来进行额外验证,它可以找到图像中点与轮廓之间的最短距离。我的假阳性处理过程包括:
- 检查边界框是否有效
- 根据它们的相对接近程度确保两个边界框相邻
如果边界框通过了相邻性和相似度指标测试,则将它们组合,并触发FedEx通知。
结果


这个检查算法并不是很稳健,因为会有许多误报和检测失败。例如,触发了这些误报。


- 每帧都需要计算边界框,存在延迟问题 - 有时会在标志不存在时误检测 - 亮度和时间对检测准确性有很大影响 - 当标志呈倾斜角度时,颜色阈值检测可以工作,但由于检查算法而无法检测到标志。
请问是否有人能够帮助我改进我的算法或建议替代的检测策略?是否有其他方法进行此检测,因为颜色阈值高度依赖于精确校准?如果可能,我想避免使用颜色阈值和多层过滤器,因为它不太健壮。非常感谢任何见解或建议!