我正试图使用计算机视觉从pdf / image发票中提取数据。为此,我使用了基于OCR的pytesseract。
这是示例发票
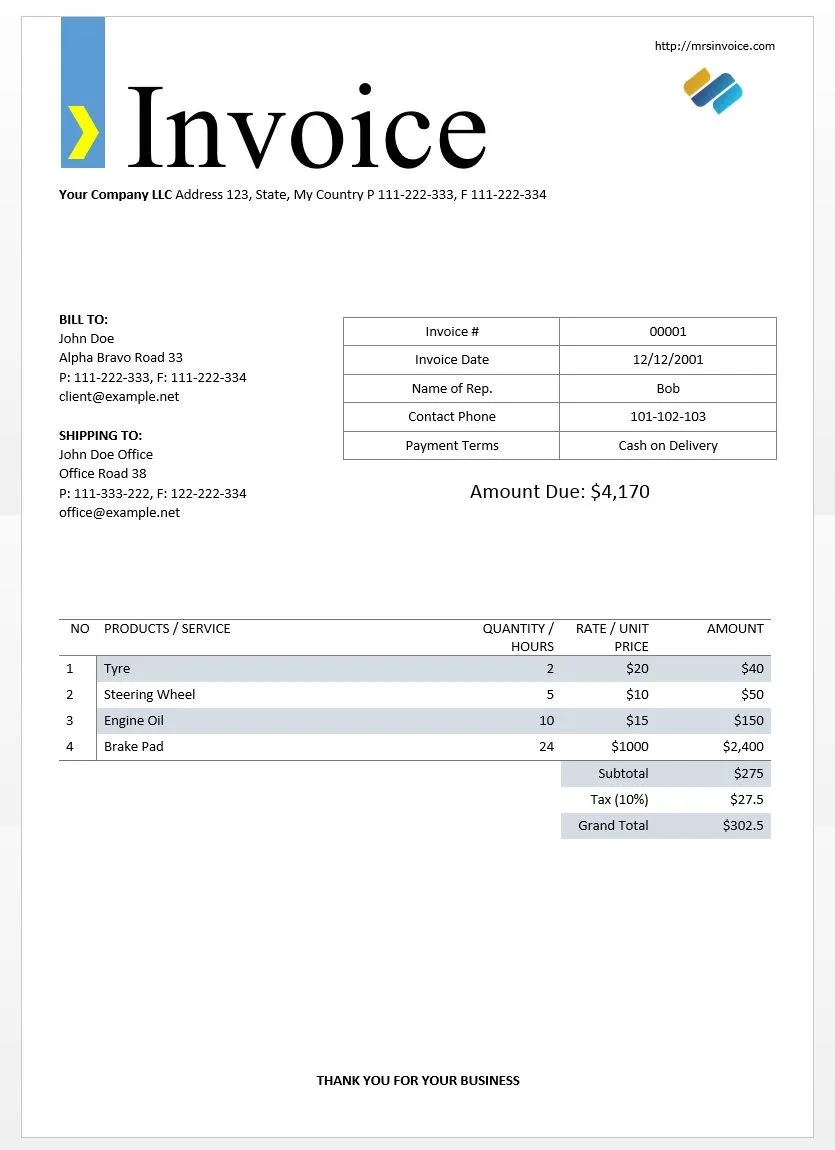 你可以在下面找到相同的代码
你可以在下面找到相同的代码
import pytesseract
img = Image.open("invoice-sample.jpg")
text = pytesseract.image_to_string(img)
print(text)
通过使用pytesseract,我获得了以下输出。
http://mrsinvoice.com
’ Invoice
Your Company LLC Address 123, State, My Country P 111-222-333, F 111-222-334
BILLTO:
fofin Oe Invoice # 00001
Alpha Bravo Road 33 Invoice Date 32/12/2001
P: 111-292-333, F: 111-222-334
client@example.net Nomecof Reps Bob
Contact Phone 101-102-103
SHIPPING TO:
eine ce Payment Terms ash on Delivery
Office Road 38
P: 111-333-222, F: 122-222-334 Amount Due: $4,170
office@example.net
NO PRODUCTS / SERVICE QUANTITY / RATE / UNIT AMOUNT
HOURS: PRICE
1 tye 2 $20 $40
2__| Steering Wheel 5 $10 $50
3 | Engine oil 10 $15 $150
4 | Brake Pad 24 $1000 $2,400
Subtotal $275
Tax (10%) $27.5
Grand Total $202.5
‘THANK YOU FOR YOUR BUSINESS
但问题在于我想提取文本,并将其分成不同的部分,如供应商名称、发票号码、项目名称和项目数量。 期望输出
{'date': (2014, 6, 4), 'invoice_number': 'EUVINS1-OF5-DE-120725895', 'amount': 35.24, 'desc': 'Invoice EUVINS1-OF5-DE-120725895 from Amazon EU'}
我也尝试过
invoice2data Python库,但它也有很多限制。我还尝试使用正则表达式和OpenCV的Canny边缘检测来分别检测文本框,但未能实现预期的结果。请问您能帮助我吗?
tesseract。Google Vision API将返回各种段落的边界框以及OCR文本,然后您可以构建一些正则表达式来检测地址块、姓名块或表格数据等。 - ZdaR