我有一个需求,想要将两个数据框合并,但没有任何关键列。
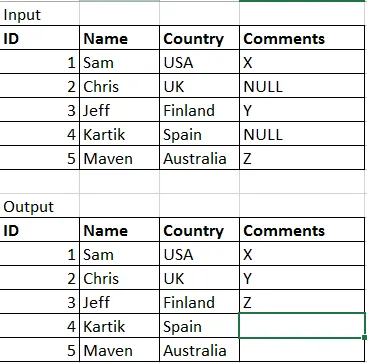 从输入表格中,我将前三列视为一个数据框,将最后一列视为另一个数据框。我的计划是对第二个数据框进行排序,然后将其与第一个数据框合并,而不使用任何关键列,以使其看起来像上面的输出。
是否可以以这种方式合并,或者是否有其他替代方法?
从输入表格中,我将前三列视为一个数据框,将最后一列视为另一个数据框。我的计划是对第二个数据框进行排序,然后将其与第一个数据框合并,而不使用任何关键列,以使其看起来像上面的输出。
是否可以以这种方式合并,或者是否有其他替代方法?
从输入表格中,我将前三列视为一个数据框,将最后一列视为另一个数据框。我的计划是对第二个数据框进行排序,然后将其与第一个数据框合并,而不使用任何关键列,以使其看起来像上面的输出。
是否可以以这种方式合并,或者是否有其他替代方法?
pd.concat或pd.append是你正在寻找的,我正在进行一些挖掘。 - ChootsMagootsdf['comments']' = df['comments'].sort_values()- C8H10N4O2