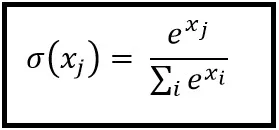我正在尝试复制一篇研究论文中的深度卷积神经网络。我已经实现了这个结构,但是在10个epochs之后,我的交叉熵损失突然增加到无限大。下面的图表可以看出。问题发生后准确率的变化可以忽略。
这里是Github仓库链接,其中包含该网络结构的图片。
经过一些研究,我认为使用AdamOptimizer或relu可能存在问题。
经过一些研究,我认为使用AdamOptimizer或relu可能存在问题。
x = tf.placeholder(tf.float32, shape=[None, 7168])
y_ = tf.placeholder(tf.float32, shape=[None, 7168, 3])
#Many Convolutions and Relus omitted
final = tf.reshape(final, [-1, 7168])
keep_prob = tf.placeholder(tf.float32)
W_final = weight_variable([7168,7168,3])
b_final = bias_variable([7168,3])
final_conv = tf.tensordot(final, W_final, axes=[[1], [1]]) + b_final
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=final_conv))
train_step = tf.train.AdamOptimizer(1e-5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(final_conv, 2), tf.argmax(y_, 2))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
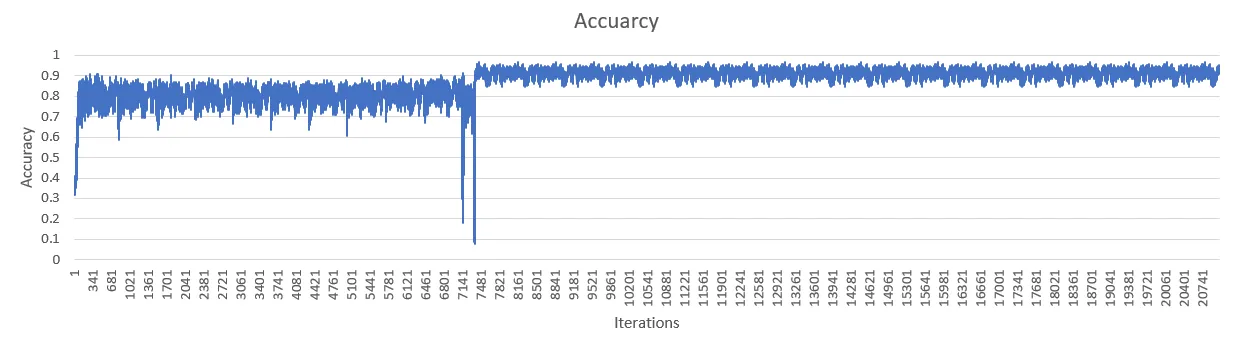
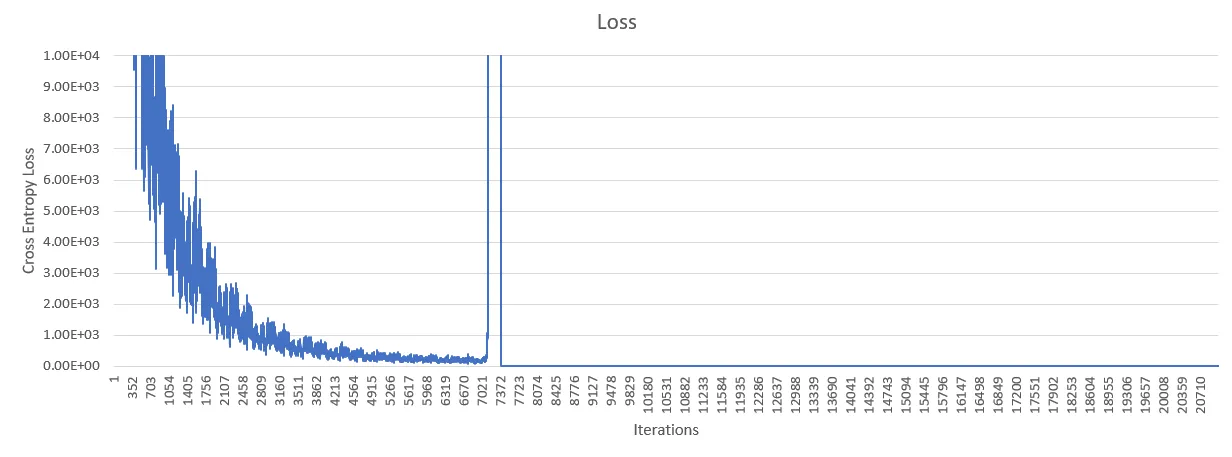
编辑 如果有人感兴趣,解决方法是我基本上输入了错误的数据。