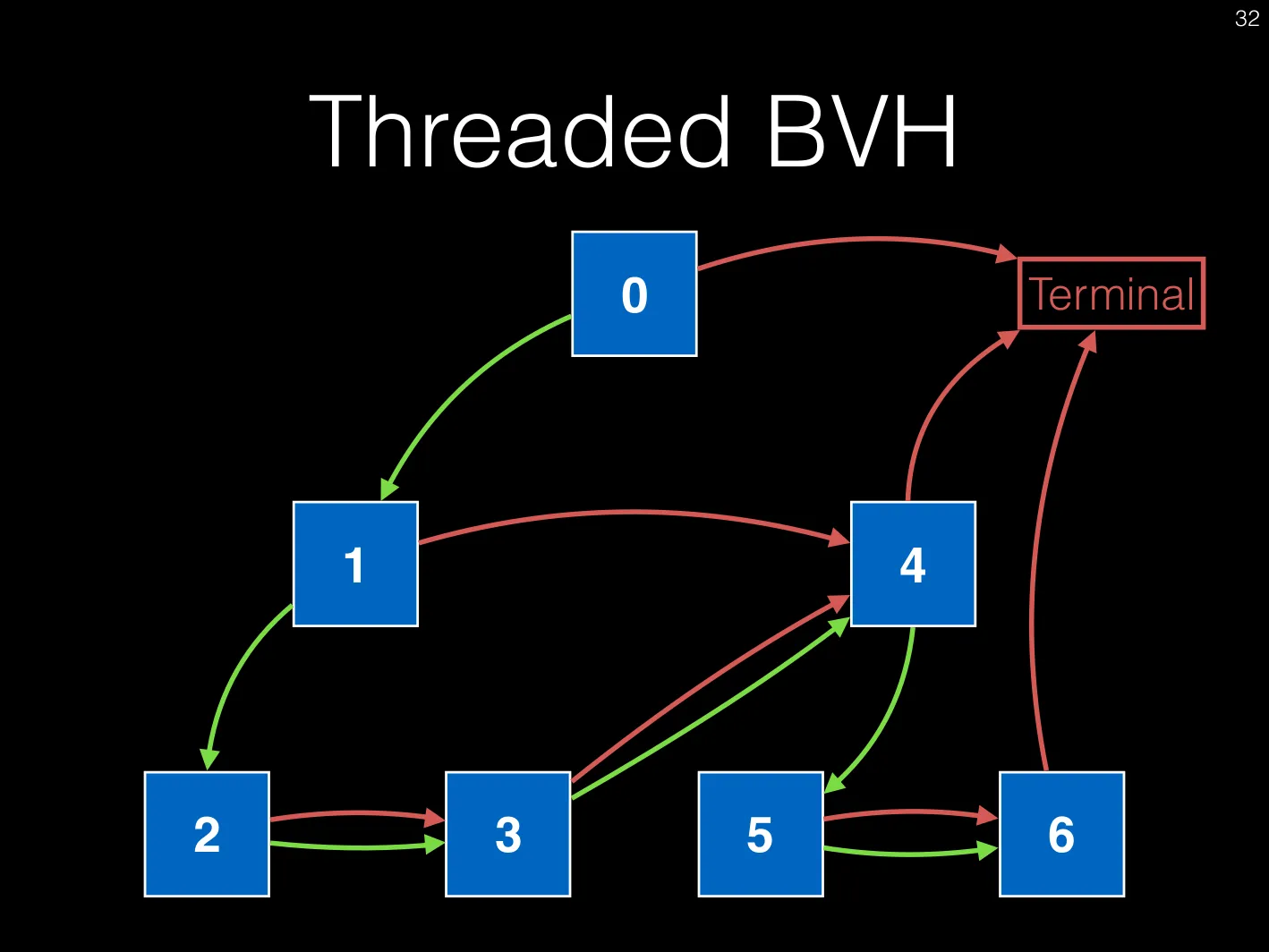
我正在使用Vulkan计算着色器开发路径跟踪器。我实现了一棵代表边界体层次结构的树。 BVH的思想是将光线相交测试需要执行的对象数量最小化。
#1天真的实现
我的第一个实现非常快,它遍历整个树直到BVH树的一个叶子节点。但是,射线可能会相交多个叶子节点。该代码会导致某些三角形未被渲染(尽管它们应该被渲染)。
int box_index = -1;
for (int i = 0; i < boxes_count; i++) {
// the first box has no parent, boxes[0].parent is set to -1
if (boxes[i].parent == box_index) {
if (intersect_box(boxes[i], ray)) {
box_index = i;
}
}
}
if (box_index > -1) {
uint a = boxes[box_index].ids_offset;
uint b = a + boxes[box_index].ids_count;
for (uint j = a; j < b; j++) {
uint triangle_id = triangle_references[j];
// triangle intersection code ...
}
}
#2 多叶片实现
我的第二个实现考虑到了可能有多个叶片相交的情况。然而,这个实现比实现 #1 慢36倍(好吧,在 #1 中我错过了一些相交测试,但仍然……)。
bool[boxes.length()] hits;
hits[0] = intersect_box(boxes[0], ray);
for (int i = 1; i < boxes_count; i++) {
if (hits[boxes[i].parent]) {
hits[i] = intersect_box(boxes[i], ray);
} else {
hits[i] = false;
}
}
for (int i = 0; i < boxes_count; i++) {
if (!hits[i]) {
continue;
}
// only leaves have ids_offset and ids_count defined (not set to -1)
if (boxes[i].ids_offset < 0) {
continue;
}
uint a = boxes[i].ids_offset;
uint b = a + boxes[i].ids_count;
for (uint j = a; j < b; j++) {
uint triangle_id = triangle_references[j];
// triangle intersection code ...
}
}
这种性能差异让我很疯狂。似乎只有像if(dynamically_modified_array[some_index])这样的单个语句对性能有巨大影响。我怀疑SPIR-V或GPU编译器不再能够发挥其优化魔力?因此,这是我的问题:
这确实是一个优化问题吗?
如果是,我可以将实现#2转换为更好的可优化版本吗?我是否可以给出优化提示?
在着色器中有一种标准方法来实现BVH树查询吗?