这里提供了一份有关从OSM中下载特征并在Python中可视化的完整说明。 我不建议使用Python读取.osm文件,因为有很多易于使用的软件(例如GDAL)可以代替你处理。
您不需要逐个处理节点、路径和关系以使用OpenStreetMap数据。
1. 从OpenStreetMap中选择要素
所有要素都用元数据进行标记,例如名称 (name=Starbucks), 建筑类型 (building=university), 或营业时间 (opening_hours=Mo-Fr 08:00-12:00,13:00-17:30)。例如,罗马竞技场就被这样标记:
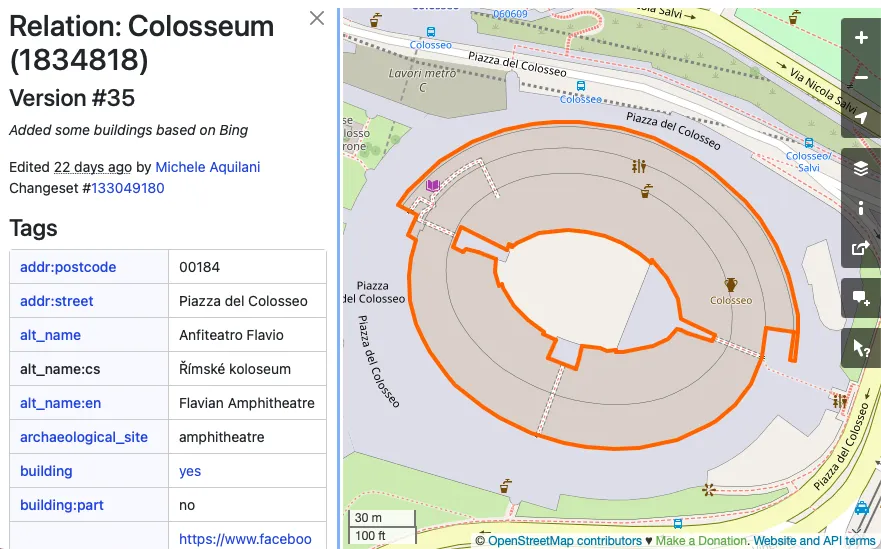
若要下载OSM功能的子集,请先确定要过滤的标签键和(可选)值的列表。例如,所有具有名称的餐厅都将被过滤为amenity=restaurant和name=*。
探索适用于您的用例的适当标签的有用资源是OSM TagInfo网站和OSM Wiki。
对于此示例,我们将下载并可视化building=university。
2. 下载匹配的功能
有三种主要方法可以从OpenStreetMap下载数据,每种方法都有其优缺点。
a. 使用API从OpenStreetMap下载功能作为.geojson
这种方法是最少资源密集型的(不需要服务器),不需要安装GDAL,并且可以使用整个地球。它需要一个免费API密钥来使用第三方OSM提取API。
curl/wget到端点并指定要下载的功能
curl --get 'https://osm.buntinglabs.com/v1/osm/extract' \
--data "tags=building=university" \
--data "api_key=YOUR_API_KEY" \
-o university_buildings.geojson
这将下载满足您tags=过滤器的地球上所有特征,以GeoJSON格式保存到university_buildings.geojson文件中。
您不需要在文件格式之间进行转换。如果您只想要一个小的提取部分,可以传递bbox=参数,并在bboxfinder上构建一个边界框。
b. 下载区域为.osm并手动本地提取
此方法可以完全在本地完成,但需要使用一个小区域(最多约10个社区)和安装GDAL。
- 从OpenStreetMap Extract缩放并下载
.osm文件。这是一个大文件,因为它是XML格式的。
- 过滤
.osm文件以获取您想要保留的要素。有关使用osmium的示例,请参见下文(c.)。
- 使用ogr2ogr将
.osm转换为.geojson。这一步非常复杂,因为GDAL将点、线和多边形存储为单独的多边形。This tutorial展示了如何将.osm转换为.geojson,或者请参见下文(c.)的示例。
c. 下载星球的.osm.pbf文件并在服务器上提取
这种方法需要大量资源,需要100GB以上的磁盘存储空间,约2天的处理时间和64GB以上的RAM。但是,它可以让您搜索整个星球。它需要安装GDAL。
通过Torrent下载planet.osm.pbf或从Geofabrik Extracts下载区域提取文件
使用osmium-tags-filter过滤您的目标特征:
osmium tags-filter -o university_buildings.osm.pbf planet.osm.pbf nwr/building=university
- 将
university_buildings.osm.pbf文件转换为.geojson
根据输出文件的大小,它可能太大了以至于无法使用GeoJSON(这是基于文本的),您应该改用GeoPackage(.gpkg)或FlatGeobuf(.fgb)。
ogr2ogr -f GeoJSON output_points.json input.osm.pbf points
ogr2ogr -f GeoJSON output_lines.json input.osm.pbf lines
然后使用 ogrmerge.py 将 output_points.json、output_lines.json 等文件进行合并。
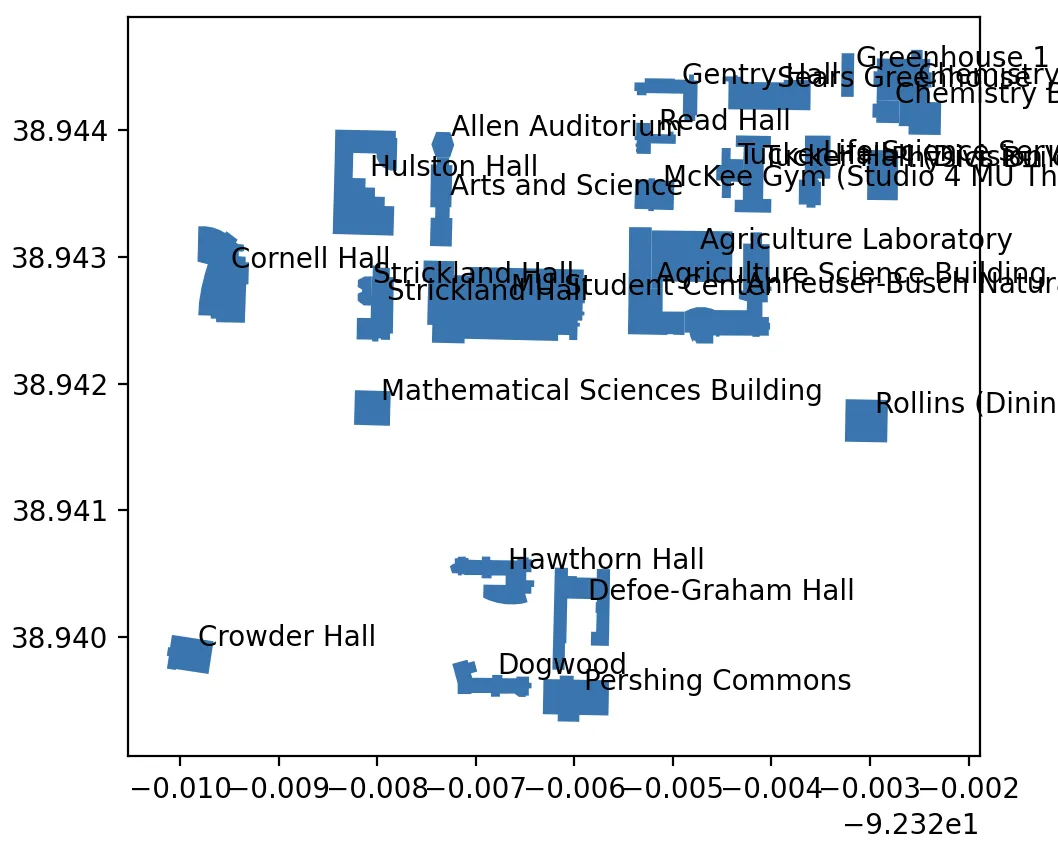
3. 可视化特征
下载完数据后,最好的做法是将它加载到 geopandas 中,这是一个内置空间支持的 pandas 扩展,也是在 Python 中可视化空间数据的最简单方式。
我们将数据加载到一个 GeoDataFrame 中,然后使用 matplotlib 进行绘图:
import matplotlib.pyplot as plt
import geopandas as gpd
gdf = gpd.read_file('university_buildings.geojson', driver='GeoJSON')
ax = gdf.plot()
for x, y, label in zip(gdf.centroid.x, gdf.centroid.y, gdf.name):
ax.annotate(label, xy=(x, y), xytext=(3, 3), textcoords="offset points")
plt.show()
这将会得到如下结果: