将整个地图传递给仅具有'a'、'b'值的列是不高效的。首先检查df列中有哪些值。然后仅为它们映射,如下所示:
>>> cols = ['one', 'two'];
>>> map = { 'a' : 'd', 'b' : 'c', 'c' : 'b', 'd' : 'a'};
>>> for col in cols:
... colSet = set(df[col].values);
... colMap = {k:v for k,v in map.items() if k in colSet};
... df.replace(to_replace={col:colMap},inplace=True);#not efficient like rly
...
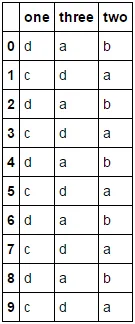
>>> df
one three two
0 d a b
1 c d a
2 d a b
3 c d a
4 d a b
5 c d a
6 d a b
7 c d a
8 d a b
9 c d a
>>>
#OR
In [12]: %%timeit
...: for col in cols:
...: colSet = set(df[col].values);
...: colMap = {k:v for k,v in map.items() if k in colSet};
...: df[col].map(colMap)
...:
...:
1 loop, best of 3: 1.93 s per loop
#OR WHEN INPLACE
In [8]: %%timeit
...: for col in cols:
...: colSet = set(df[col].values);
...: colMap = {k:v for k,v in map.items() if k in colSet};
...: df[col]=df[col].map(colMap)
...:
...:
1 loop, best of 3: 2.18 s per loop
那也是可能的:
df = pd.DataFrame({'one':['a' , 'b']*5, 'two':['c' , 'd']*5, 'three':['a' , 'd']*5})
map = { 'a' : 'd', 'b' : 'c', 'c' : 'b', 'd' : 'a'}
cols = ['one','two']
def func(s):
if s.name in cols:
s=s.map(map)
return s
print df.apply(func)
同时注意重叠的键(即,如果您想并行更改a到b和b到c,但不是像a->b->c那样)...
>>> cols = ['one', 'two'];
>>> map = ;
>>> mapCols = ;
>>> df.replace(to_replace=mapCols,inplace=True);
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "Q:\Miniconda3\envs\py27a\lib\site-packages\pandas\core\generic.py", line 3352, in replace
raise ValueError("Replacement not allowed with "
ValueError: Replacement not allowed with overlapping keys and values
df.replace是一个 Pandas 库中的函数,用于替换数据框中的值。更多信息请参考:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.replace.html - DeepSpace