在一个pylab程序中(可能也可以是matlab程序),我有一个numpy数字数组表示距离:
我感兴趣的事件是当距离低于某个阈值时,我想计算这些事件的持续时间。用
如何有效地在numpy数组中检测这种序列呢?
以下是一些Python代码,说明了我的问题:第四个圆点需要很长时间才能出现(如果没有,请增加数组大小)。
d[t] 是时间 t 的距离(我的数据的时间跨度为len(d)个时间单位)。我感兴趣的事件是当距离低于某个阈值时,我想计算这些事件的持续时间。用
b = d<threshold 得到一个布尔数组很容易,问题就变成了计算b 中 True-only 单词的长度序列。但是我不知道如何高效地做到这一点(即使用numpy原语),我不得不遍历数组并进行手动更改检测(即当值从False变为True时初始化计数器,在值为True时增加计数器,并在值回到False时将计数器输出到序列)。但这是非常慢的。如何有效地在numpy数组中检测这种序列呢?
以下是一些Python代码,说明了我的问题:第四个圆点需要很长时间才能出现(如果没有,请增加数组大小)。
from pylab import *
threshold = 7
print '.'
d = 10*rand(10000000)
print '.'
b = d<threshold
print '.'
durations=[]
for i in xrange(len(b)):
if b[i] and (i==0 or not b[i-1]):
counter=1
if i>0 and b[i-1] and b[i]:
counter+=1
if (b[i-1] and not b[i]) or i==len(b)-1:
durations.append(counter)
print '.'
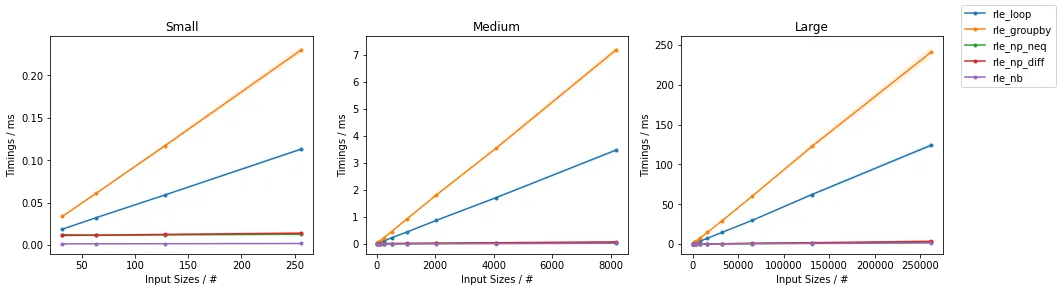
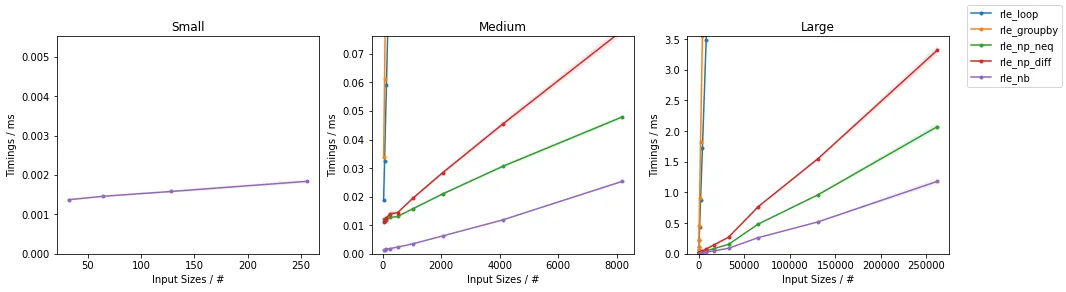
np.nan的运行中会出现错误。正在修复。 - Thomas Browne