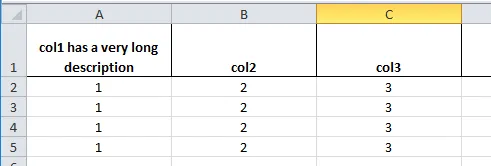
我想要得到以下输出。所有的行和列都是自动换行的,除了表头:
import pandas as pd
import pandas.io.formats.style
import os
from pandas import ExcelWriter
import numpy as np
from xlsxwriter.utility import xl_rowcol_to_cell
writer = pd.ExcelWriter('test1.xlsx',engine='xlsxwriter',options={'strings_to_numbers': True},date_format='mmmm dd yyyy')
df = pd.read_csv("D:\\Users\\u700216\\Desktop\\Reports\\CD_Counts.csv")
df.to_excel(writer,sheet_name='Sheet1',startrow=1 , startcol=1, header=True, index=False, encoding='utf8')
workbook = writer.book
worksheet = writer.sheets['Sheet1']
format = workbook.add_format()
format1 = workbook.add_format({'bold': True, 'align' : 'left'})
format.set_align('Center')
format1.set_align('Center')
format.set_text_wrap()
format1.set_text_wrap()
worksheet.set_row(0, 20, format1)
worksheet.set_column('A:Z', 30, format)
writer.save()
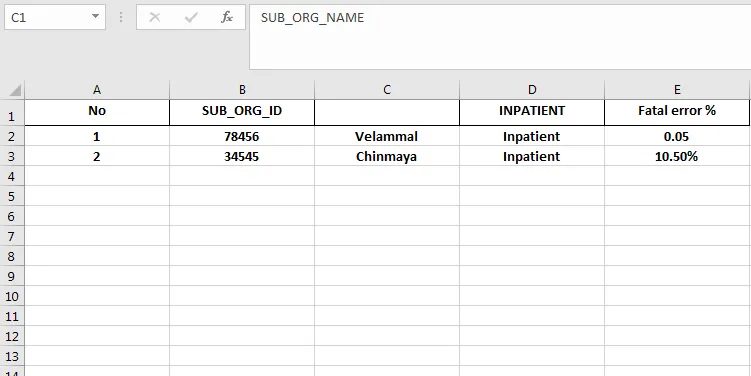
除标题外,格式应用于所有行和列。我不知道为什么格式未应用于第一列(标题),或者我想手动添加列标题编号,例如0、1、2等,以便关闭标题,从而格式化所有行和列。
在上面的截图中,A1到E1没有应用文本换行,C1列有很多空格的标题。如果我手动单击换行,它会对齐,否则所有标题都不使用文本换行格式化。

pd.core.format.header_style = None。 - jmcnamara