我想创建一个新的列,该列等于该行所有列的最大值。
以下是一个示例:
library(data.table)
data <- data.table(head(iris))
data[ , Species := NULL]
data
Sepal.Length Sepal.Width Petal.Length Petal.Width
1: 5.1 3.5 1.4 0.2
2: 4.9 3.0 1.4 0.2
3: 4.7 3.2 1.3 0.2
4: 4.6 3.1 1.5 0.2
5: 5.0 3.6 1.4 0.2
6: 5.4 3.9 1.7 0.4
我不能在这里真正使用max函数,因为它将找到所有列的最大值,例如data[, max_value := max(Sepal.Length, Sepal.Width, Petal.Length, Petal.Width)]。我想要的是像这样的东西:
Sepal.Length Sepal.Width Petal.Length Petal.Width max_value
1: 5.1 3.5 1.4 0.2 5.1
2: 4.9 3.0 1.4 0.2 4.9
3: 4.7 3.2 1.3 0.2 4.7
4: 4.6 3.1 1.5 0.2 4.6
5: 5.0 3.6 1.4 0.2 5.0
6: 5.4 3.9 1.7 0.4 5.4
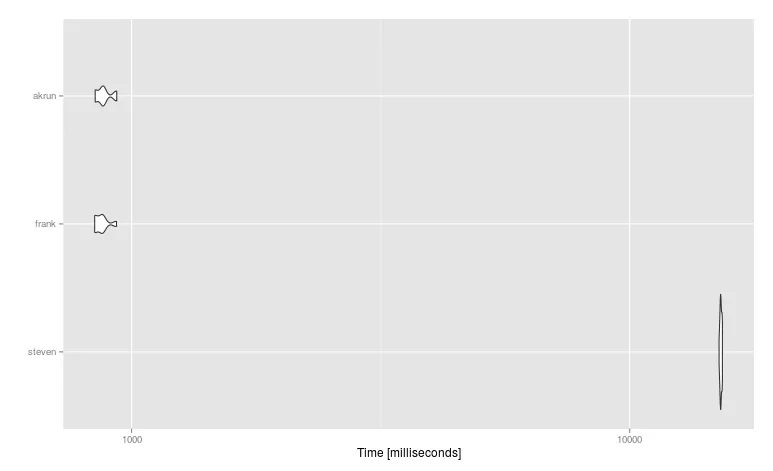
data[,mymax:=apply(.SD,1,max)]的操作会将其转换为一个中间步骤的矩阵。 - Frank